What are embedding models
Last Updated : 03 Jun, 2025
Embedding models are the type of machine learning model designed to represent data in a continuous, low dimensional vector space called embedding. Embedding are numerical representation of a piece of information for like text, documents, images, audio etc. which captures the semantic meaning of what is being embedded which makes it robust for many industry applications.
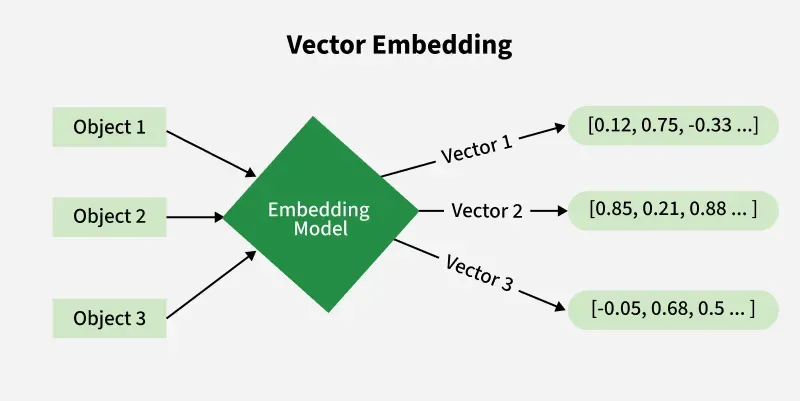 Embedding
Embedding Here, each object is transformed into a numerical vector using an embedding model capturing semantic features and relationship between different data points.
Working of embedding models
 Working of embedding models
Working of embedding modelsThe process begins with raw input data which can be of any form such as text, images, or audio. This raw data is often unstructured and needs to be preprocessed to make it suitable for machine learning models.
Once the input preprocessing is done the next step involves extracting meaningful features that represent the underlying structure or patterns within the data. For textual data we can use models like Word2Vec, GloVe, or BERT. This stage transforms the data into a numerical vector representation that captures essential characteristics.
3.Dimensionality reduction
After extracting features the data exists in a high dimensional space which can be computationally expensive and prone to overfitting. Dimensionality reduction techniques like Principal Component Analysis (PCA) are used to reduce the feature space while preserving the most informative aspects which makes the resulting representation more compact and efficient.
4. Output embedding
The final output is an embedding which is a low dimensional vector that encodes important features in a machine understandable form. These embeddings are used in various downstream tasks such as classification, clustering, recommendation, and similarity search.
Types of embedding models
1. Word embedding models
These models aims to convert words into numerical vectors that capture semantic meanings and relationships between different words. For example:
- Word2vec: This model learns word embeddings by predicting a word based on its context or predicting context based on a word.
- GloVe (Global vectors for vector representation): uses word co-occurrence statistics from a large corpus to create embeddings.
2. Audio embedding models
These models aims to convert speech data into embeddings which are useful for tasks like speech recognition etc. For example:
- VGGish: An embedding model based on CNN used for audio particularly music and speech.
- Wav2vec: This model generates embeddings for raw speech audio which is effective for speech to text tasks.
3. Sentence or document embedding models
These models aims to convert sentences or documents into numerical vectors representing entire sentences or documents rather than just individual words.
- Doc2vec: This model is an extension of Word2vec that generates embeddings for whole documents by considering the context of the words in the document.
- InferSent: This is a sentence encoder that learns to map sentences into embeddings for various tasks.
4. Image embedding models
These models represent images as vectors, enabling tasks like image recognition and retrieval.
- CNN (Convolutional neural networks): Machine learning models like ResNet and VGG extract features from images and are used to generate image classification and recognition embeddings.
- CLIP (Contrastive language image pre training): This model connects images and textual descriptions by generating embeddings for both and aligning them in the same vector space.
How do we choose the right embedding model?
1. Type of data
- The choice of embedding model heavily depends on the type of data you are working with.
- For text data models like Word2Vec, GloVe, or transformer-based embeddings like BERT are suitable.
- For image data convolutional neural networks (CNNs) or models like ResNet and can be used to generate embeddings.
- For audio, models like wav2vec are more appropriate.
2. Required task
- The specific task which you are trying to accomplish through embedding plays an important role in selecting an embedding model.
- For example if you need embeddings for sentiment analysis contextual models like BERT are often better than static embeddings.
- On the other hand if want to build a recommendation system, collaborative filtering or specialized recommendation embeddings may work better.
3. Speed and accuracy
- Larger and more complex models like BERT or CLIP give highly accurate output embeddings but require significant computational resources and time.
- We should choose the right balance between speed and accuracy which ensures that our application is both effective and efficient.
4. Size of dataset
- The volume of available training data also influences the choice of embedding model.
- Machine learning models like BERT performs best with large datasets while simpler models like Word2Vec are effective with smaller datasets.
- If our dataset is limited we can use pre trained embeddings from large models and fine tuning them on your specific domain we can get better performance without the need for extensive training data.
Applications
- Image embeddings transforms images into numerical representations to perform image search and image generation.
- Product embeddings gives personalized recommendations in the field of e commerce by finding similar products based on user preferences and purchase history.
- Audio embeddings can be used to transform speech data into embeddings to music discovery and speech recognition.
- Time series data can be converted into embeddings to uncover hidden patterns and make accurate predictions.
- Document embeddings can be used to transform documents into embeddings that can be used in search engines.
Similar Reads
What is Text Embedding? Text embeddings are vector representations of text that map the original text into a mathematical space where words or sentences with similar meanings are located near each other. Unlike traditional one-hot encoding, where each word is represented as a sparse vector with a single '1' for the corresp
5 min read
What are Language Models in NLP? Language models are a fundamental component of natural language processing (NLP) and computational linguistics. They are designed to understand, generate, and predict human language. These models analyze the structure and use of language to perform tasks such as machine translation, text generation,
9 min read
What are Embedding in Machine Learning? In recent years, embeddings have emerged as a core idea in machine learning, revolutionizing the way we represent and understand data. In this article, we delve into the world of embeddings, exploring their importance, applications, and the underlying techniques used to generate them. Table of Conte
15+ min read
Word Embeddings in NLP Word Embeddings are numeric representations of words in a lower-dimensional space, that capture semantic and syntactic information. They play a important role in Natural Language Processing (NLP) tasks. Here, we'll discuss some traditional and neural approaches used to implement Word Embeddings, suc
14 min read
Masked Language Models Masked Language Models (MLMs) are a type of machine learning model designed to predict missing or "masked" words in a sentence. These models are trained on large datasets of text where certain words are intentionally hidden during training. The goal of the model is to guess the hidden word based on
5 min read