Token Classification in Natural Language Processing
Last Updated : 12 Jun, 2025
Token classification is a core task in Natural Language Processing (NLP) where each token (typically a word or sub-word) in a sequence is assigned a label. This task is important for extracting structured information from unstructured text. It does so by labeling tokens with specific categories such as entity types, parts of speech, or syntactic chunks. It helps models to better understand both the semantic meaning and the grammatical structure of the language.
What is a Token ?
Tokens are the smaller units of a text, typically separated by whitespace (like spaces or newlines) and punctuation marks (such as commas or periods). For example, Consider the sentence
"The quick brown fox jumps over the lazy dog."
The tokens for this sentence would be:
"The", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog", "."
Word level vs Sub-word level (BERT-style)
1. In traditional NLP pipelines, tokenization is done at the word level, meaning each token corresponds directly to a word in the sentence.
Text: "running"
Tokens: ["running"]
This approach is simple, but has drawbacks as it struggles with :
- Rare or misspelled words
- Change in structure and formation of words
- Out of vocabulary terms
2. Modern transformer-based models like BERT, RoBERTa, and GPT use sub-word tokenization algorithms such as WordPiece, Byte Pair Encoding (BPE) or Unigram models. These break words into smaller, meaningful fragments.
Text: "running"
Tokens: ["run", "##ing"]
"##ing" shows that it is a continuation of a previous sub-word. This method helps with:
- Efficiently handling rare or unseen words
- Sharing sub-word representations across different words (e.g., “runner”, “running”, “run”)
BIO/IOB tagging scheme
The IOB tagging scheme also referred to as BIO (Beginning, Inside, Outside) is a widely used labeling format in token classification tasks such as Named Entity Recognition (NER), chunking, and semantic role labeling. This format helps models identify spans of consecutive tokens that together represent a meaningful entity (like a person’s name, organization, or location).
Components of IOB/BIO Tags
Each token is assigned one of these tags
Tags | Meaning |
|---|
B | Beginning of a chunk/entity |
|---|
I | Inside a chunk/entity |
|---|
O | Outside of any chunk/entity |
|---|
Applications of Token Classification
1. Named Entity Recognition (NER)
NER classified entities typically include categories such as person names, locations, organizations, dates, and more. The task involves assigning a specific label to each token in the text, indicating the type of entity it belongs to, or even a neutral label (often "O") if the token is not part of any named entity.
Code Example:
Python from transformers import pipeline classifier = pipeline("ner") classifier("Hello I'm Mary and I live in Amsterdam.") Output:
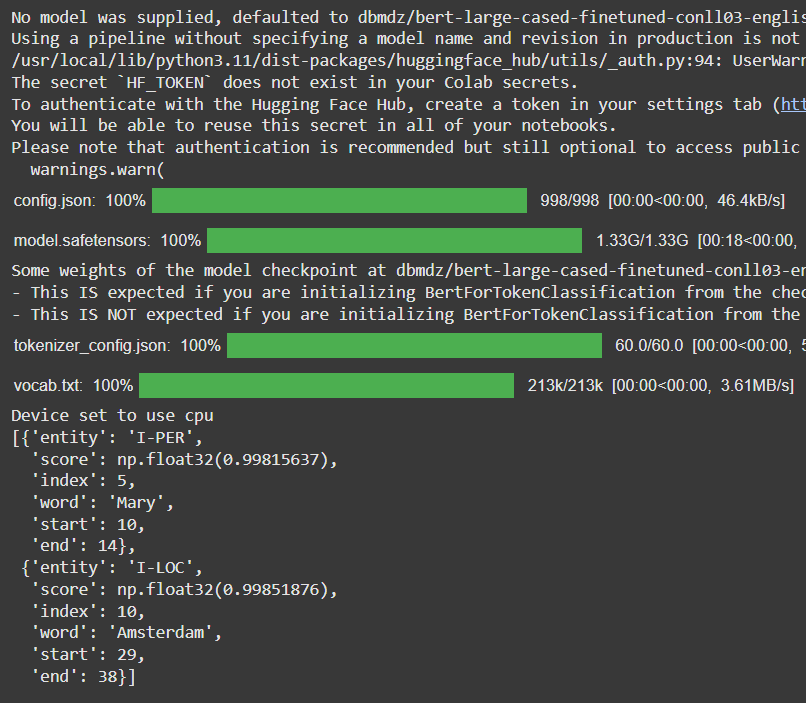 Output for NER model
Output for NER modelInterpretation:
- "Mary" labeled as a Person (
I-PER) with 99.8% confidence - "Amsterdam" labeled as a Location (
I-LOC) with 99.85% confidence
2. Part-of-Speech (POS) Tagging
POS tagging is a classic token classification task, where the goal is to assign a grammatical category (such as noun, verb, adjective, etc.) to each word in a sentence. The model processes the input text and labels each token based on its syntactic role within the sentence.
Code Example:
Python from transformers import pipeline classifier = pipeline("token-classification", model = "vblagoje/bert-english-uncased-finetuned-pos") classifier("Hello I'm Mary and I live in Amsterdam.") Output:
 Output for POS model
Output for POS modelInterpretation:
| Token | POS Tag | Meaning | Confidence |
|---|
| hello | INTJ | Interjection (e.g., greetings) | 99.68% |
| i | PRON | Pronoun | 99.94% |
| ' | AUX | Auxiliary verb (part of "I'm") | 99.67% |
| m | AUX | Auxiliary verb ("am") | 99.65% |
| mary | PROPN | Proper noun | 99.85% |
| and | CCONJ | Coordinating conjunction | 99.92% |
| i | PRON | Pronoun | 99.95% |
| live | VERB | Main verb | 99.86% |
| in | ADP | Adposition (preposition) | 99.94% |
| amsterdam | PROPN | Proper noun | 99.88% |
. | PUNCT | Punctuation | 99.96% |
Challenges in Token Classification
- Sub-word Token Handling: Sub-word tokenization splits words into smaller units, complicating token-level labeling.
For example, "playing" → ["play", "##ing"]. The challenge lies in aligning word-level labels with sub-word tokens. A common solution is to assign the label only to the first sub-word and mask the rest during training and evaluation. - Imbalanced Label Distribution: In tasks like NER, the "O" class dominates, making the model biased toward non-entity predictions. This results in poor performance for rare labels. To address this, oversampling techniques are used to ensure the model pays attention to minority classes.
- Domain Adaptation: Pretrained models often fail on specialized domains like medical or legal texts due to unfamiliar terms. This mismatch reduces performance. Fine-tuning or using domain adapted models like BioBERT or LegalBERT helps bridge the vocabulary and context gap.
- Label Ambiguity: Words like "Apple" may refer to a company or a fruit, depending on context. Such ambiguity confuses models in the absence of strong contextual clues. Transformer models like BERT use contextual embeddings to simplify meanings, but errors still occur in subtle or low-resource contexts.
Similar Reads
Top 7 Applications of NLP (Natural Language Processing) In the past, did you ever imagine that you could talk to your phone and get things done? Or that your phone would talk back to you! This has become a pretty normal thing these days with Siri, Alexa, Google Assistant, etc. You can ask any possible questions ranging from “What’s the weather outside†t
6 min read
What is Tokenization in Natural Language Processing (NLP)? Tokenization is a fundamental process in Natural Language Processing (NLP), essential for preparing text data for various analytical and computational tasks. In NLP, tokenization involves breaking down a piece of text into smaller, meaningful units called tokens. These tokens can be words, subwords,
4 min read
Natural Language Processing with R Natural Language Processing (NLP) is a field of artificial intelligence (AI) that enables machines to understand and process human language. R, known for its statistical capabilities, provides a wide range of libraries to perform various NLP tasks. Understanding Natural Language ProcessingNLP involv
4 min read
Building a Rule-Based Chatbot with Natural Language Processing A rule-based chatbot follows a set of predefined rules or patterns to match user input and generate an appropriate response. The chatbot can’t understand or process input beyond these rules and relies on exact matches making it ideal for handling repetitive tasks or specific queries.Pattern Matching
4 min read
Augmented Transition Networks in Natural Language Processing Augmented Transition Networks (ATNs) are a powerful formalism for parsing natural language, playing a significant role in the early development of natural language processing (NLP). Developed in the late 1960s and early 1970s by William Woods, ATNs extend finite state automata to include additional
8 min read