Random Forest Regression in Python
Last Updated : 30 May, 2025
A random forest is an ensemble learning method that combines the predictions from multiple decision trees to produce a more accurate and stable prediction. It is a type of supervised learning algorithm that can be used for both classification and regression tasks.
In regression task we can use Random Forest Regression technique for predicting numerical values. It predicts continuous values by averaging the results of multiple decision trees.
Working of Random Forest Regression
Random Forest Regression works by creating multiple of decision trees each trained on a random subset of the data. The process begins with Bootstrap sampling where random rows of data are selected with replacement to form different training datasets for each tree. After this we do feature sampling where only a random subset of features is used to build each tree ensuring diversity in the models.
After the trees are trained each tree make a prediction and the final prediction for regression tasks is the average of all the individual tree predictions and this process is called as Aggregation.
 Random Forest Regression Model Working
Random Forest Regression Model WorkingThis approach is beneficial because individual decision trees may have high variance and are prone to overfitting especially with complex data. However by averaging the predictions from multiple decision trees Random Forest minimizes this variance leading to more accurate and stable predictions and hence improving generalization of model.
Implementing Random Forest Regression in Python
We will be implementing random forest regression on salaries data.
1. Importing Libraries
Here we are importing numpy, pandas, matplotlib, seaborn and scikit learn.
- RandomForestRegressor: This is the regression model that is based upon the Random Forest model.
- LabelEncoder: This class is used to encode categorical data into numerical values.
- KNNImputer: This class is used to impute missing values in a dataset using a k-nearest neighbors approach.
- train_test_split: This function is used to split a dataset into training and testing sets.
- StandardScaler: This class is used to standardize features by removing the mean and scaling to unit variance.
- f1_score: This function is used to evaluate the performance of a classification model using the F1 score.
- RandomForestRegressor: This class is used to train a random forest regression model.
- cross_val_score: This function is used to perform k-fold cross-validation to evaluate the performance of a model
Python import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import sklearn import warnings from sklearn.preprocessing import LabelEncoder from sklearn.impute import KNNImputer from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.metrics import f1_score from sklearn.ensemble import RandomForestRegressor from sklearn.ensemble import RandomForestRegressor from sklearn.model_selection import cross_val_score warnings.filterwarnings('ignore') 2. Importing Dataset
Now let's load the dataset in the panda's data frame. For better data handling and leveraging the handy functions to perform complex tasks in one go. You can download dataset from here.
Python df= pd.read_csv('/content/Position_Salaries.csv') print(df) Output:
 Dataset Python
Dataset Python Output:
 Info of the dataset
Info of the dataset3. Data Preparation
Here the code will extracts two subsets of data from the Dataset and stores them in separate variables.
- Extracting Features: It extracts the features from the DataFrame and stores them in a variable named
X. - Extracting Target Variable: It extracts the target variable from the DataFrame and stores it in a variable named
y.
Python X = df.iloc[:,1:2].values y = df.iloc[:,2].values
4. Random Forest Regressor Model
The code processes categorical data by encoding it numerically, combines the processed data with numerical data and trains a Random Forest Regression model using the prepared data.
- RandomForestRegressor: It builds multiple decision trees and combines their predictions.
- n_estimators=10: Defines the number of decision trees in the Random Forest.
- random_state=0: Ensures the randomness in model training is controlled for reproducibility.
- oob_score=True: Enables out-of-bag scoring which evaluates the model's performance using data not seen by individual trees during training.
- LabelEncoder(): Converts categorical variables (object type) into numerical values, making them suitable for machine learning models.
- apply(label_encoder.fit_transform): Applies the LabelEncoder transformation to each categorical column, converting string labels into numbers.
- concat(): Combines the numerical and encoded categorical features horizontally into one dataset which is then used as input for the model.
Python import pandas as pd from sklearn.ensemble import RandomForestRegressor from sklearn.preprocessing import LabelEncoder label_encoder = LabelEncoder() x_categorical = df.select_dtypes(include=['object']).apply(label_encoder.fit_transform) x_numerical = df.select_dtypes(exclude=['object']).values x = pd.concat([pd.DataFrame(x_numerical), x_categorical], axis=1).values regressor = RandomForestRegressor(n_estimators=10, random_state=0, oob_score=True) regressor.fit(x, y)
5. Making predictions and Evaluating
The code evaluates the trained Random Forest Regression model:
- oob_score_: Retrive out-of-bag (OOB) score which estimates the model's generalization performance.
- Makes predictions using the trained model and stores them in the 'predictions' array.
- Evaluates the model's performance using the Mean Squared Error (MSE) and R-squared (R2) metrics.
Python from sklearn.metrics import mean_squared_error, r2_score oob_score = regressor.oob_score_ print(f'Out-of-Bag Score: {oob_score}') predictions = regressor.predict(x) mse = mean_squared_error(y, predictions) print(f'Mean Squared Error: {mse}') r2 = r2_score(y, predictions) print(f'R-squared: {r2}') Output:
Out-of-Bag Score: 0.644879832593859
Mean Squared Error: 2647325000.0
R-squared: 0.9671801245316117
6. Visualizing
Now let's visualize the results obtained by using the RandomForest Regression model on our salaries dataset.
- Creates a grid of prediction points covering the range of the feature values.
- Plots the real data points as blue scatter points.
- Plots the predicted values for the prediction grid as a green line.
- Adds labels and a title to the plot for better understanding.
Python import numpy as np X_grid = np.arange(min(X[:, 0]), max(X[:, 0]), 0.01) # Only the first feature X_grid = X_grid.reshape(-1, 1) X_grid = np.hstack((X_grid, np.zeros((X_grid.shape[0], 2)))) # Pad with zeros plt.scatter(X[:, 0], y, color='blue', label="Actual Data") plt.plot(X_grid[:, 0], regressor.predict(X_grid), color='green', label="Random Forest Prediction") plt.title("Random Forest Regression Results") plt.xlabel('Position Level') plt.ylabel('Salary') plt.legend() plt.show() Output:
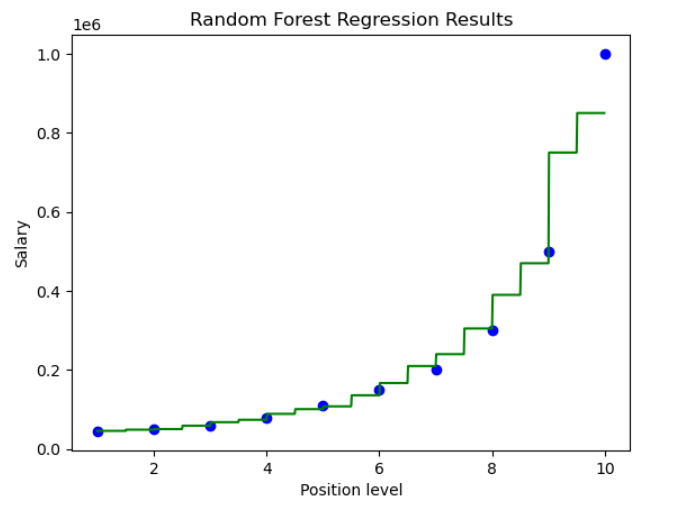
7. Visualizing a Single Decision Tree from the Random Forest Model
The code visualizes one of the decision trees from the trained Random Forest model. Plots the selected decision tree, displaying the decision-making process of a single tree within the ensemble.
Python from sklearn.tree import plot_tree import matplotlib.pyplot as plt tree_to_plot = regressor.estimators_[0] plt.figure(figsize=(20, 10)) plot_tree(tree_to_plot, feature_names=df.columns.tolist(), filled=True, rounded=True, fontsize=10) plt.title("Decision Tree from Random Forest") plt.show() Output:
 Applications of Random Forest Regression
Applications of Random Forest Regression
The Random forest regression has a wide range of real-world problems including:
- Predicting continuous numerical values: Predicting house prices, stock prices or customer lifetime value.
- Identifying risk factors: Detecting risk factors for diseases, financial crises or other negative events.
- Handling high-dimensional data: Analyzing datasets with a large number of input features.
- Capturing complex relationships: Modeling complex relationships between input features and the target variable.
Advantages of Random Forest Regression
- Handles Non-Linearity: It can capture complex, non-linear relationships in the data that other models might miss.
- Reduces Overfitting: By combining multiple decision trees and averaging predictions it reduces the risk of overfitting compared to a single decision tree.
- Robust to Outliers: Random Forest is less sensitive to outliers as it aggregates the predictions from multiple trees.
- Works Well with Large Datasets: It can efficiently handle large datasets and high-dimensional data without a significant loss in performance.
- Handles Missing Data: Random Forest can handle missing values by using surrogate splits and maintaining high accuracy even with incomplete data.
- No Need for Feature Scaling: Unlike many other algorithms Random Forest does not require normalization or scaling of the data.
Disadvantages of Random Forest Regression
- Complexity: It can be computationally expensive and slow to train especially with a large number of trees and high-dimensional data. Due to this it may not be suitable for real-time predictions especially with a large number of trees.
- Less Interpretability: Since it uses many trees it can be harder to interpret compared to simpler models like linear regression or decision trees.
- Memory Intensive: Storing multiple decision trees for large datasets require significant memory resources.
- Overfitting on Noisy Data: While Random Forest reduces overfitting, it can still overfit if the data is highly noisy especially with a large number of trees.
- Sensitive to Imbalanced Data: It may perform poorly if the dataset is highly imbalanced like one class is significantly more frequent than another.
Random Forest Regression has become a important tool for continuous prediction tasks with advantages over traditional decision trees. Its capability to handle high-dimensional data, capture complex relationships and reduce overfitting has made it useful.
Similar Reads
Machine Learning Algorithms Machine learning algorithms are essentially sets of instructions that allow computers to learn from data, make predictions, and improve their performance over time without being explicitly programmed. Machine learning algorithms are broadly categorized into three types: Supervised Learning: Algorith
8 min read
Top 15 Machine Learning Algorithms Every Data Scientist Should Know in 2025 Machine Learning (ML) Algorithms are the backbone of everything from Netflix recommendations to fraud detection in financial institutions. These algorithms form the core of intelligent systems, empowering organizations to analyze patterns, predict outcomes, and automate decision-making processes. Wi
14 min read
Linear Model Regression
Ordinary Least Squares (OLS) using statsmodelsOrdinary Least Squares (OLS) is a widely used statistical method for estimating the parameters of a linear regression model. It minimizes the sum of squared residuals between observed and predicted values. In this article we will learn how to implement Ordinary Least Squares (OLS) regression using P
3 min read
Linear Regression (Python Implementation)Linear regression is a statistical method that is used to predict a continuous dependent variable i.e target variable based on one or more independent variables. This technique assumes a linear relationship between the dependent and independent variables which means the dependent variable changes pr
14 min read
Multiple Linear Regression using Python - MLLinear regression is a statistical method used for predictive analysis. It models the relationship between a dependent variable and a single independent variable by fitting a linear equation to the data. Multiple Linear Regression extends this concept by modelling the relationship between a dependen
4 min read
Polynomial Regression ( From Scratch using Python )Prerequisites Linear RegressionGradient DescentIntroductionLinear Regression finds the correlation between the dependent variable ( or target variable ) and independent variables ( or features ). In short, it is a linear model to fit the data linearly. But it fails to fit and catch the pattern in no
5 min read
Bayesian Linear RegressionLinear regression is based on the assumption that the underlying data is normally distributed and that all relevant predictor variables have a linear relationship with the outcome. But In the real world, this is not always possible, it will follows these assumptions, Bayesian regression could be the
10 min read
How to Perform Quantile Regression in PythonIn this article, we are going to see how to perform quantile regression in Python. Linear regression is defined as the statistical method that constructs a relationship between a dependent variable and an independent variable as per the given set of variables. While performing linear regression we a
4 min read
Isotonic Regression in Scikit LearnIsotonic regression is a regression technique in which the predictor variable is monotonically related to the target variable. This means that as the value of the predictor variable increases, the value of the target variable either increases or decreases in a consistent, non-oscillating manner. Mat
6 min read
Stepwise Regression in PythonStepwise regression is a method of fitting a regression model by iteratively adding or removing variables. It is used to build a model that is accurate and parsimonious, meaning that it has the smallest number of variables that can explain the data. There are two main types of stepwise regression: F
6 min read
Least Angle Regression (LARS)Regression is a supervised machine learning task that can predict continuous values (real numbers), as compared to classification, that can predict categorical or discrete values. Before we begin, if you are a beginner, I highly recommend this article. Least Angle Regression (LARS) is an algorithm u
3 min read
Linear Model Classification
Regularization
K-Nearest Neighbors (KNN)
Support Vector Machines
ML - Stochastic Gradient Descent (SGD) Stochastic Gradient Descent (SGD) is an optimization algorithm in machine learning, particularly when dealing with large datasets. It is a variant of the traditional gradient descent algorithm but offers several advantages in terms of efficiency and scalability, making it the go-to method for many d
8 min read
Decision Tree
Ensemble Learning