Scrapy is a web scraping library that is used to scrape, parse and collect web data. For all these functions we are having a pipelines.py file which is used to handle scraped data through various components (known as class) which are executed sequentially.
In this article, we will be learning through the methods defined for this pipeline's file and will show different examples of it.
Setting Up Project
Let's, first, create a scrapy project. For that make sure that Python and PIP are installed in the system. Then run the given commands below one by one to create a scrapy project similar to the one which we will be using in this article.
Step 1: Let's first create a virtual environment in a folder named GFGScrapy and activate that virtual environment there.
# To create a folder named GFGScrapy mkdir GFGScrapy cd GFGScrapy # making virtual env there. virtualenv cd scripts # activating it activate cd..
Hence, after running all these commands, we will get the output as shown:
 Creating virtual environment
Creating virtual environment Step 2: Now it's time to create a scrapy project. For that Make sure that scrapy is installed in the system or not. If not installed, install it using the given command below.
pip install scrapy
Now to create a scrapy project use the, given command below and also create a spider.
# projEct name is scrapytutorial scrapy startproject scrapytutorial cd scrapytutorial scrapy genspider spider_to_crawl https://quotes.toscrape.com
Then the output of the project directory looks like the one given in the image. (Please refer this if you want to know more about a scrapy project and get familiar with it).
 Directory structure
Directory structure Let's have a look at our spider_to_crawl.py file present inside our spiders folder. This is the file where we are writing the URL where our spider has to crawl and also a method named parse() which is used to describe what should be done with the data scraped by the spider.
This file is automatically generated by "scrapy genspider" command used above. The file is named after the spider's name. Below given is the default file generated.
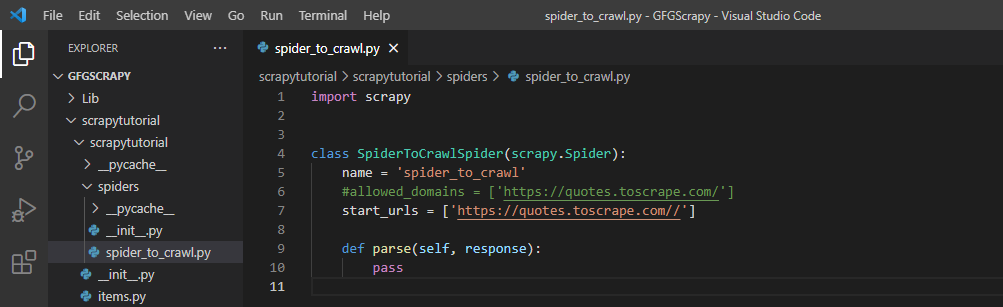 spider_to_crawl.py
spider_to_crawl.py Item pipeline is a pipeline method that is written inside pipelines.py file and is used to perform the below-given operations on the scraped data sequentially. The various operations we can perform on the scraped items are listed below:
- Parse the scraped files or data.
- Store the scraped data in databases.
- Validating and checking the data obtained.
- Converting files from one format to another. eg to JSON.
We will be performing some of these operations in the examples below.
Operations are performed sequentially since we are using settings.py file to describe the order in which the operations should be done. i.e. we can mention which operation to be performed first and which to be performed next. This is usually done when we are performing several operations on the items.
Let's first see the inner structure of a default pipeline file. Below is the default class mentioned in that file.
 Default pipelines.py file
Default pipelines.py file For performing different operations on items we have to declare a separated component( classes in the file) which consists of various methods, used for performing operations. The pipelines file in default has a class named after the project name. We can also create our own classes to write what operations they have to perform. If any pipelines file consists of more than one class then we should mention their execution order explicitly. The structure of components are defined below:
Each component (class) must have one default function named process_item(). This is the default method which is always called inside the class or component of the pipelines file.
Syntax: process_item( self, item, spider )
Parameters:
- self : This is reference to the self object calling the method.
- item : These are the items list scraped by the spider
- spider : mentions the spider used to scrape.
The return type of this method is the modified or unmodified item object or an error will be raised if any fault is found in item.
This method is also used to call other method in this class which can be used to modify or store data.
Additional methods: These methods are used along with the above-mentionedself-object method to gain extra control over the items.
| Method | Description |
|---|
| open_spider(self,spider) | Spider object which is opened and a reference to self object are the parameters. ( These are default cases of python language). Returns nothing except the fact that it is used to either make some changes or open a file or close a file. |
| close_spider(self,spider) | Spider object which is closed and a reference to self-object. It also either is used to modify the file or open or close it. |
| from_crawler(cls, crawler) | Crawler object that is specified. This method is used to give pipeline accessibility to all the core components of the scrapy settings so that pipelines can enhance their functionality, |
Apart from all these methods, we can also create our own method to perform more operations like if we want to store some data then we can have the component that initializes the database and create tables in it, Another component may be there which will add the data to the database.
Before we move ahead and refer to examples, an important point to note is that we should have to register all the components (classes) of the pipelines.py file in the settings.py of the folder structure. This is done to maintain an ordering of the components to be executed and hence produce accurate results.
Creating Items to be passed over files.
One more thing to note is that we will require a description of what our item will contain in items.py file. Hence our items.py file contains the below-given code:
Python3 # Define here the models for your scraped items import scrapy class ScrapytutorialItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() Quote = scrapy.Field() #only one field that it of Quote.
We will require this file to be imported in our spider_to_crawl.py file. Hence in this way we can create items to be passed to pipeline. We will mainly be using the Wisdom quotes web page where we can get several quotes based on their authors and respective tags and then we will modify and use items pipelines on the scraped data throughout the example.
Example 1: Converting scraped data to JSON format
To convert the data in JSON format we will be using JSON library of python along with its dumps() method.
The idea is that we will get the scraped data in pipelines.py file and then we will open a file named result.json (if not already present then it will be created automatically) and write all the JSON data in it.
- open_spider() will be called to open the file (result.json) when spider starts crawling.
- close_spider() will be called to close the file when spider is closed and scraping is over.
- process_item() will always be called (since it is default) and will be mainly responsible for converting the data to JSON format and print the data to the file. We will be using the concept of python web frameworks, i.e. how they convert backend retrieved data to JSON and other formats.
Hence the code in our pipelines.py looks like this:
Python3 from itemadapter import ItemAdapter import json class ScrapytutorialPipeline: def process_item(self, item, spider): # calling dumps to create json data. line = json.dumps(dict(item)) + "\n" self.file.write(line) return item def open_spider(self, spider): self.file = open('result.json', 'w') def close_spider(self, spider): self.file.close()
Our spider_to_crawl.py:
Python3 import scrapy from ..items import ScrapytutorialItem class SpiderToCrawlSpider(scrapy.Spider): name = 'spider_to_crawl' start_urls = ['https://quotes.toscrape.com/'] def parse(self, response): # creating items dictionary items = ScrapytutorialItem() Quotes_all = response.xpath('//div/div/div/span[1]') # These paths are based on the selectors for quote in Quotes_all: #extracting data items['Quote'] = quote.css('p::text').extract() yield items Output:

Explanation:
After using the command "scrapy crawl spider_to_crawl", The below-given steps are going to take place.
- The spider is crawled due to which result.json file is created. Now the spider scrapes the web page and collects the data in Quotes_all Variable. Then we will send each data from this variable one by one to our pipelines.py file.
- We receive item variables from spider in pipelines.py file which is, then converted to JSON using the dumps() method, and then the output is written in the opened file.
This is the JSON file which got created:

Example 2: Pipeline to upload data to database in SQLite3
Now we are going to present an items pipeline that will scrape the content of the web and store it on the database table defined by us. For simplicity, we will be using the SQLite3 database.
So we will use the idea of how to implement SQLite3 in python to create a pipeline that will receive data from spider scraping and will insert that data to the table in the database created.
spider_to_crawl.py:
Python3 import scrapy from ..items import ScrapytutorialItem class SpiderToCrawlSpider(scrapy.Spider): name = 'spider_to_crawl' start_urls = ['https://quotes.toscrape.com/'] def parse(self, response): # creating items dictionary items = ScrapytutorialItem() Quotes_all = response.xpath('//div/div/div/span[1]') # These paths are based on the selectors # extracting data for quote in Quotes_all: items['Quote'] = quote.css('::text').extract() yield items We are mentioning the pipeline methods below which are to be written in the pipelines.py File so that the database will be created:
pipelines.py file
Python3 from itemadapter import ItemAdapter import sqlite3 class ScrapytutorialPipeline(object): # init method to initialize the database # and create connection and tables def __init__(self): self.create_conn() self.create_table() # create connection method to create # database or use database to store scraped data def create_conn(self): self.conn = sqlite3.connect("mydata.db") self.curr = self.conn.cursor() # Create table method # using SQL commands to create table def create_table(self): self.curr.execute("""DROP TABLE IF EXISTS firsttable""") self.curr.execute("""create table firsttable( Quote text )""") # store items to databases. def process_item(self, item, spider): self.putitemsintable(item) return item def putitemsintable(self,item): self.curr.execute("""insert into firsttable values (?)""",( item['Quote'][0], # extracting item. )) self.conn.commit()
Output:
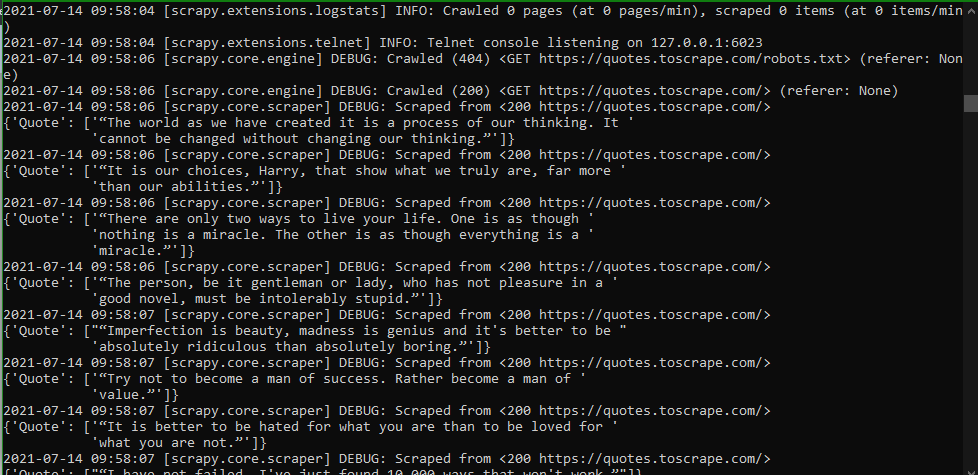

Explanation:
After using the command "scrapy crawl spider_to_crawl", the below-given steps are going to take place
- In spider.py we had mentioned the code that our spider should go to that site and extract all data mentioned in the URL format and then will create items list of it and pass that list to the pipelines.py file for further processing.
- We are also creating an items object to contain data to be passed and item it at items.py file in the directory.
- Then when the spider crawls it collects data in items object and transfers it to the pipelines and what happens next is already clear from the above code with hints in comments. pipelines.py file creates a database and stores all the incoming items.
- Here the init() method is called which is called a default method always in any python file. It then calls all other methods which are used to create a table and initialize the database.
- Then process_item() method is called which is used to call a method named putitemintable() where data is added to the database. Then, after executing this method the reference is returned to the spider to pass another item to be operated.
Similar Reads
Implementing Web Scraping in Python with Scrapy Nowadays data is everything and if someone wants to get data from webpages then one way to use an API or implement Web Scraping techniques. In Python, Web scraping can be done easily by using scraping tools like BeautifulSoup. But what if the user is concerned about performance of scraper or need to
5 min read
Getting Started With Scrapy
Scrapy Basics
Scrapy - Command Line ToolsPrerequisite: Implementing Web Scraping in Python with Scrapy Scrapy is a python library that is used for web scraping and searching the contents throughout the web. It uses Spiders which crawls throughout the page to find out the content specified in the selectors. Hence, it is a very handy tool to
5 min read
Scrapy - Item LoadersIn this article, we are going to discuss Item Loaders in Scrapy. Scrapy is used for extracting data, using spiders, that crawl through the website. The obtained data can also be processed, in the form, of Scrapy Items. The Item Loaders play a significant role, in parsing the data, before populating
15+ min read
Scrapy - Item PipelineScrapy is a web scraping library that is used to scrape, parse and collect web data. For all these functions we are having a pipelines.py file which is used to handle scraped data through various components (known as class) which are executed sequentially. In this article, we will be learning throug
10 min read
Scrapy - SelectorsScrapy Selectors as the name suggest are used to select some things. If we talk of CSS, then there are also selectors present that are used to select and apply CSS effects to HTML tags and text. In Scrapy we are using selectors to mention the part of the website which is to be scraped by our spiders
7 min read
Scrapy - ShellScrapy is a well-organized framework, used for large-scale web scraping. Using selectors, like XPath or CSS expressions, one can scrape data seamlessly. It allows systematic crawling, and scraping the data, and storing the content in different file formats. Scrapy comes equipped with a shell, that h
9 min read
Scrapy - SpidersScrapy is a free and open-source web-crawling framework which is written purely in python. Thus, scrapy can be installed and imported like any other python package. The name of the package is self-explanatory. It is derived from the word 'scraping' which literally means extracting desired substance
11 min read
Scrapy - Feed exportsScrapy is a fast high-level web crawling and scraping framework written in Python used to crawl websites and extract structured data from their pages. It can be used for many purposes, from data mining to monitoring and automated testing. This article is divided into 2 sections:Creating a Simple web
5 min read
Scrapy - Link ExtractorsIn this article, we are going to learn about Link Extractors in scrapy. "LinkExtractor" is a class provided by scrapy to extract links from the response we get while fetching a website. They are very easy to use which we'll see in the below post. Scrapy - Link Extractors Basically using the "LinkEx
5 min read
Scrapy - SettingsScrapy is an open-source tool built with Python Framework. It presents us with a strong and robust web crawling framework that can easily extract the info from the online page with the assistance of selectors supported by XPath. We can define the behavior of Scrapy components with the help of Scrapy
7 min read
Scrapy - Sending an E-mailPrerequisites: Scrapy Scrapy provides its own facility for sending e-mails which is extremely easy to use, and it’s implemented using Twisted non-blocking IO, to avoid interfering with the non-blocking IO of the crawler. This article discusses how mail can be sent using scrapy. For this MailSender
2 min read
Scrapy - ExceptionsPython-based Scrapy is a robust and adaptable web scraping platform. It provides a variety of tools for systematic, effective data extraction from websites. It helps us to automate data extraction from numerous websites. Scrapy Python Scrapy describes the spider that browses websites and gathers dat
7 min read
Data Collection and Management
Data Extraction and Export
How to Convert Scrapy item to JSON?Prerequisite:Â scrapyJSON Scrapy is a web scraping tool used to collect web data and can also be used to modify and store data in whatever form we want. Whenever data is being scraped by the spider of scrapy, we are converting that raw data to items of scrapy, and then we will pass that item for fur
8 min read
Saving scraped items to JSON and CSV file using ScrapyIn this article, we will see how to use crawling with Scrapy, and, Exporting data to JSON and CSV format. We will scrape data from a webpage, using a Scrapy spider, and export the same to two different file formats. Here we will extract from the link  http://quotes.toscrape.com/tag/friendship/. This
6 min read
How to get Scrapy Output File in XML File?Prerequisite: Implementing Web Scraping in Python with Scrapy Scrapy provides a fast and efficient method to scrape a website. Web Scraping is used to extract the data from websites. In Scrapy we create a spider and then use it to crawl a website. In this article, we are going to extract population
2 min read
Scraping a JSON response with ScrapyScrapy is a popular Python library for web scraping, which provides an easy and efficient way to extract data from websites for a variety of tasks including data mining and information processing. In addition to being a general-purpose web crawler, Scrapy may also be used to retrieve data via APIs.
2 min read
Logging in ScrapyScrapy is a fast high-level web crawling and scraping framework written in Python used to crawl websites and extract structured data from their pages. It can be used for many purposes, from data mining to monitoring and automated testing. As developers, we spend most of our time debugging than writi
3 min read
Appliaction And Projects
How to use Scrapy to parse PDF pages online?Prerequisite: Scrapy, PyPDF2, URLLIB In this article, we will be using Scrapy to parse any online PDF without downloading it onto the system. To do that we have to use the PDF parser or editor library of Python know as PyPDF2. PyPDF2 is a pdf parsing library of python, which provides various method
3 min read
How to download Files with Scrapy ?Scrapy is a fast high-level web crawling and web scraping framework used to crawl websites and extract structured data from their pages. It can be used for a wide range of purposes, from data mining to monitoring and automated testing. In this tutorial, we will be exploring how to download files usi
8 min read
Automated Website Scraping using ScrapyScrapy is a Python framework for web scraping on a large scale. It provides with the tools we need to extract data from websites efficiently, processes it as we see fit, and store it in the structure and format we prefer. Zyte (formerly Scrapinghub), a web scraping development and services company,
5 min read
Writing Scrapy Python Output to JSON fileIn this article, we are going to see how to write scrapy output into a JSON file in Python. Using  scrapy command-line shell This is the easiest way to save data to JSON is by using the following command: scrapy crawl <spiderName> -O <fileName>.json This will generate a file with a provi
2 min read
Pagination using Scrapy - Web Scraping with PythonPagination using Scrapy. Web scraping is a technique to fetch information from websites. Scrapy is used as a Python framework for web scraping. Getting data from a normal website is easier, and can be just achieved by just pulling the HTML of the website and fetching data by filtering tags. But what
3 min read
Email Id Extractor Project from sites in Scrapy PythonScrapy is open-source web-crawling framework written in Python used for web scraping, it can also be used to extract data for general-purpose. First all sub pages links are taken from the main page and then email id are scraped from these sub pages using regular expression. This article shows the e
8 min read
Scraping Javascript Enabled Websites using Scrapy-SeleniumScrapy-selenium is a middleware that is used in web scraping. scrapy do not support scraping modern sites that uses javascript frameworks and this is the reason that this middleware is used with scrapy to scrape those modern sites.Scrapy-selenium provide the functionalities of selenium that help in
4 min read
How to use Scrapy Items?In this article, we will scrape Quotes data using scrapy items, from the webpage https://quotes.toscrape.com/tag/reading/. The main objective of scraping, is to prepare structured data, from unstructured resources. Scrapy Items are wrappers around, the dictionary data structures. Code can be written
9 min read
How To Follow Links With Python Scrapy ?In this article, we will use Scrapy, for scraping data, presenting on linked webpages, and, collecting the same. We will scrape data from the website 'https://quotes.toscrape.com/'. Creating a Scrapy Project Scrapy comes with an efficient command-line tool, also called the 'Scrapy tool'. Commands ar
9 min read
Difference between BeautifulSoup and Scrapy crawlerWeb scraping is a technique to fetch data from websites. While surfing on the web, many websites don’t allow the user to save data for personal use. One way is to manually copy-paste the data, which both tedious and time-consuming. Web Scraping is the automation of the data extraction process from w
3 min read
Python - How to create an ARP Spoofer using Scapy?ARP spoofing is a malicious attack in which the hacker sends falsified ARP in a network. Every node in a connected network has an ARP table through which we identify the IP address and the MAC address of the connected devices. What aim to send an ARP broadcast to find our desired IP which needs to b
6 min read