Python | Pandas Merging, Joining and Concatenating
Last Updated : 14 Jun, 2025
Pandas DataFrame helps for working with data organized in rows and columns. When we're working with multiple datasets we need to combine them in different ways. Pandas provides three simple methods like merging, joining and concatenating. These methods help us to combine data in various ways whether it's matching columns, using indexes or stacking data on top of each other. In this article, we'll see these methods.
Concatenating DataFrames
Concatenating DataFrames means combining them either by stacking them on top of each other (vertically) or placing them side by side (horizontally). In order to Concatenate dataframe, we use different methods which are as follows:
1. Concatenating DataFrame using .concat()
To concatenate DataFrames, we use the pd.concat() function. This function allows us to combine multiple DataFrames into one by specifying the axis (rows or columns).
Here we will be loading and printing the custom dataset, then we will perform the concatenation using pd.concat().
Python import pandas as pd data1 = {'Name': ['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age': [27, 24, 22, 32], 'Address': ['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification': ['Msc', 'MA', 'MCA', 'Phd']} data2 = {'Name': ['Abhi', 'Ayushi', 'Dhiraj', 'Hitesh'], 'Age': [17, 14, 12, 52], 'Address': ['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification': ['Btech', 'B.A', 'Bcom', 'B.hons']} df = pd.DataFrame(data1, index=[0, 1, 2, 3]) df1 = pd.DataFrame(data2, index=[4, 5, 6, 7]) print(df, "\n\n", df1) Output:
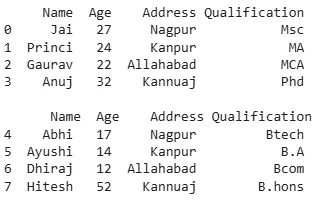 output
outputNow we apply .concat function in order to concat two dataframe.
Python frames = [df, df1] res1 = pd.concat(frames) res1
Output:
 output
output2. Concatenating DataFrames by Setting Logic on Axes
We can modify the concatenation by setting logic on the axes. Specifically we can choose whether to take the Union (join='outer') or Intersection (join='inner') of columns.
Python import pandas as pd data1 = {'Name': ['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age': [27, 24, 22, 32], 'Address': ['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification': ['Msc', 'MA', 'MCA', 'Phd'], 'Mobile No': [97, 91, 58, 76]} data2 = {'Name': ['Gaurav', 'Anuj', 'Dhiraj', 'Hitesh'], 'Age': [22, 32, 12, 52], 'Address': ['Allahabad', 'Kannuaj', 'Allahabad', 'Kannuaj'], 'Qualification': ['MCA', 'Phd', 'Bcom', 'B.hons'], 'Salary': [1000, 2000, 3000, 4000]} df = pd.DataFrame(data1, index=[0, 1, 2, 3]) df1 = pd.DataFrame(data2, index=[2, 3, 6, 7]) print(df, "\n\n", df1) Output:
 output
outputNow we set axes join = inner for intersection of dataframe which keeps only the common columns.
Python res2 = pd.concat([df, df1], axis=1, join='inner') res2
Output:
 output
outputNow we set axes join = outer for union of dataframe which keeps all columns from both DataFrames.
Python res2 = pd.concat([df, df1], axis=1, sort=False) res2
Output:
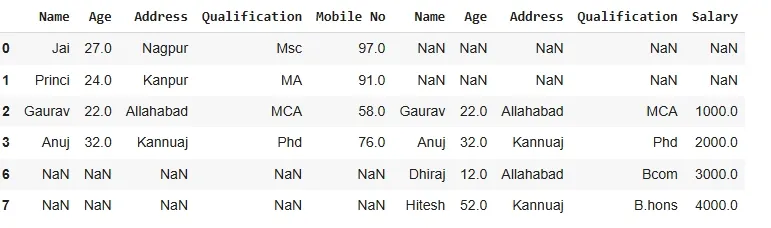 output
output3. Concatenating DataFrames by Ignoring Indexes
Sometimes the indexes of the original DataFrames may not be relevant. We can ignore the indexes and reset them using the ignore_index argument. This is useful when we don't want to carry over any index information.
Python import pandas as pd data1 = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Msc', 'MA', 'MCA', 'Phd'], 'Mobile No': [97, 91, 58, 76]} data2 = {'Name':['Gaurav', 'Anuj', 'Dhiraj', 'Hitesh'], 'Age':[22, 32, 12, 52], 'Address':['Allahabad', 'Kannuaj', 'Allahabad', 'Kannuaj'], 'Qualification':['MCA', 'Phd', 'Bcom', 'B.hons'], 'Salary':[1000, 2000, 3000, 4000]} df = pd.DataFrame(data1,index=[0, 1, 2, 3]) df1 = pd.DataFrame(data2, index=[2, 3, 6, 7]) print(df, "\n\n", df1) Output:
 output
outputNow we are going to apply ignore_index as an argument.
Python res = pd.concat([df, df1], ignore_index=True) res
Output:
 output
output4. Concatenating DataFrame with group keys :
If we want to retain information about the DataFrame from which each row came, we can use the keys argument. This assigns a label to each group of rows based on the source DataFrame.
Python import pandas as pd data1 = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Msc', 'MA', 'MCA', 'Phd']} data2 = {'Name':['Abhi', 'Ayushi', 'Dhiraj', 'Hitesh'], 'Age':[17, 14, 12, 52], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Btech', 'B.A', 'Bcom', 'B.hons']} df = pd.DataFrame(data1,index=[0, 1, 2, 3]) df1 = pd.DataFrame(data2, index=[4, 5, 6, 7]) print(df, "\n\n", df1) Output:
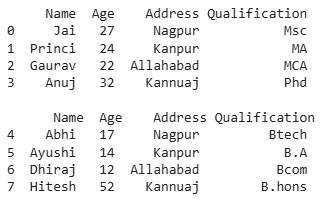 output
outputHere we will use keys as an argument. The keys argument creates a hierarchical index where each row is labeled with the source DataFrame (df1 or df2).
Python frames = [df, df1 ] res = pd.concat(frames, keys=['x', 'y']) res
Output:
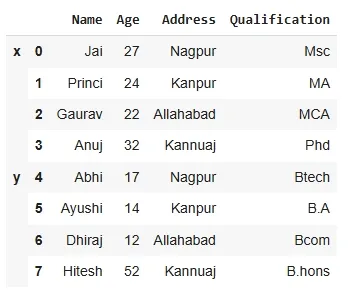 output
output5. Concatenating Mixed DataFrames and Series
We can also concatenate a mix of Series and DataFrames. If we include a Series in the list, it will automatically be converted to a DataFrame and we can specify the column name.
Python import pandas as pd data1 = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Msc', 'MA', 'MCA', 'Phd']} df = pd.DataFrame(data1,index=[0, 1, 2, 3]) s1 = pd.Series([1000, 2000, 3000, 4000], name='Salary') print(df, "\n\n", s1) Output:
 output
outputHere we are going to mix Series and dataframe together.
Python res = pd.concat([df, s1], axis=1) res
Output:
 output
outputMerging DataFrame
Merging DataFrames in Pandas is similar to performing SQL joins. It is useful when we need to combine two DataFrames based on a common column or index. The merge() function provides flexibility for different types of joins.
There are four basic ways to handle the join (inner, left, right and outer) depending on which rows must retain their data.
 1. Merging DataFrames Using One Key
1. Merging DataFrames Using One Key
We can merge DataFrames based on a common column by using the on argument. This allows us to combine the DataFrames where values in a specific column match.
Python import pandas as pd data1 = {'key': ['K0', 'K1', 'K2', 'K3'], 'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32],} data2 = {'key': ['K0', 'K1', 'K2', 'K3'], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Btech', 'B.A', 'Bcom', 'B.hons']} df = pd.DataFrame(data1) df1 = pd.DataFrame(data2) print(df, "\n\n", df1) Output:
 output
outputNow here we are using .merge() with one unique key combination.
Python res = pd.merge(df, df1, on='key') res
Output:
 output
output2. Merging DataFrames Using Multiple Keys
We can also merge DataFrames based on more than one column by passing a list of column names to the on argument.
Python import pandas as pd data1 = {'key': ['K0', 'K1', 'K2', 'K3'], 'key1': ['K0', 'K1', 'K0', 'K1'], 'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32],} data2 = {'key': ['K0', 'K1', 'K2', 'K3'], 'key1': ['K0', 'K0', 'K0', 'K0'], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Btech', 'B.A', 'Bcom', 'B.hons']} df = pd.DataFrame(data1) df1 = pd.DataFrame(data2) print(df, "\n\n", df1) Output:
 output
outputNow we merge dataframe using multiple keys.
Python res1 = pd.merge(df, df1, on=['key', 'key1']) res1
Output:
 output
output3. Merging DataFrames Using the how Argument
We use how argument to merge specifies how to find which keys are to be included in the resulting table. If a key combination does not appear in either the left or right tables, the values in the joined table will be NA. Here is a summary of the how options and their SQL equivalent names:
| MERGE METHOD | JOIN NAME | DESCRIPTION |
|---|
| left | LEFT OUTER JOIN | Use keys from left frame only |
| right | RIGHT OUTER JOIN | Use keys from right frame only |
| outer | FULL OUTER JOIN | Use union of keys from both frames |
| inner | INNER JOIN | Use intersection of keys from both frames |
Python import pandas as pd data1 = {'key': ['K0', 'K1', 'K2', 'K3'], 'key1': ['K0', 'K1', 'K0', 'K1'], 'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32],} data2 = {'key': ['K0', 'K1', 'K2', 'K3'], 'key1': ['K0', 'K0', 'K0', 'K0'], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Btech', 'B.A', 'Bcom', 'B.hons']} df = pd.DataFrame(data1) df1 = pd.DataFrame(data2) print(df, "\n\n", df1) Output:
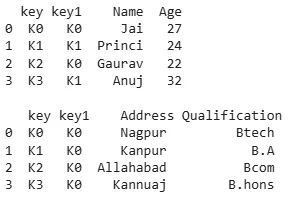 output
outputNow we set how = 'left' in order to use keys from left frame only. In this it includes all rows from the left DataFrame and only matching rows from the right.
Python res = pd.merge(df, df1, how='left', on=['key', 'key1']) res
Output:
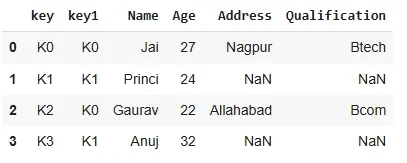 output
output Now we set how = 'right' in order to use keys from right frame only. In this it includes all rows from the right DataFrame and only matching rows from the left.
Python res1 = pd.merge(df, df1, how='right', on=['key', 'key1']) res1
Output:
 output
output Now we set how = 'outer' in order to get union of keys from dataframes. In this it combines all rows from both DataFrames, filling missing values with NaN.
Python res2 = pd.merge(df, df1, how='outer', on=['key', 'key1']) res2
Output:
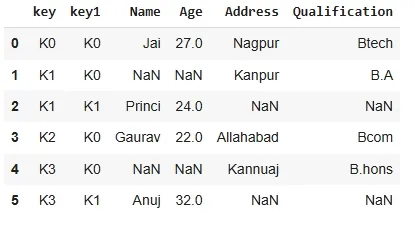 output
output Now we set how = 'inner' in order to get intersection of keys from dataframes. In this it only includes rows where there is a match in both DataFrames.
Python res3 = pd.merge(df, df1, how='inner', on=['key', 'key1']) res3
Output:
 output
outputJoining DataFrame
The .join() method in Pandas is used to combine columns of two DataFrames based on their indexes. It's a simple way of merging two DataFrames when the relationship between them is primarily based on their row indexes. It is used when we want to combine DataFrames along their indexes rather than specific columns.
1. Joining DataFrames Using .join()
If both DataFrames have the same index, we can use the .join() function to combine their columns. This method is useful when we want to merge DataFrames based on their row indexes rather than columns.
Python import pandas as pd data1 = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32]} data2 = {'Address':['Allahabad', 'Kannuaj', 'Allahabad', 'Kannuaj'], 'Qualification':['MCA', 'Phd', 'Bcom', 'B.hons']} df = pd.DataFrame(data1,index=['K0', 'K1', 'K2', 'K3']) df1 = pd.DataFrame(data2, index=['K0', 'K2', 'K3', 'K4']) print(df, "\n\n", df1) Output:
 output
outputNow we are using .join() method in order to join dataframes
Python Output:
 output
output Now we use how = 'outer' in order to get union
Python res1 = df.join(df1, how='outer') res1
Output:
 output
output2. Joining DataFrames Using the "on" Argument
If we want to join DataFrames based on a column (rather than the index), we can use the on argument. This allows us to specify which column(s) should be used to align the two DataFrames.
Python import pandas as pd data1 = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32], 'Key':['K0', 'K1', 'K2', 'K3']} data2 = {'Address':['Allahabad', 'Kannuaj', 'Allahabad', 'Kannuaj'], 'Qualification':['MCA', 'Phd', 'Bcom', 'B.hons']} df = pd.DataFrame(data1) df1 = pd.DataFrame(data2, index=['K0', 'K2', 'K3', 'K4']) print(df, "\n\n", df1) Output:
 output
outputNow we are using .join with “on” argument.
Python res2 = df.join(df1, on='Key') res2
Output:
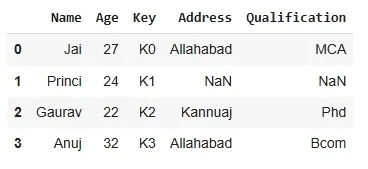 output
output3. Joining DataFrames with Different Index Levels (Multi-Index)
In some cases, we may be working with DataFrames that have multi-level indexes. The .join() function also supports joining DataFrames that have different index levels by specifying the index levels.
Python import pandas as pd data1 = {'Name':['Jai', 'Princi', 'Gaurav'], 'Age':[27, 24, 22]} data2 = {'Address':['Allahabad', 'Kannuaj', 'Allahabad', 'Kanpur'], 'Qualification':['MCA', 'Phd', 'Bcom', 'B.hons']} df = pd.DataFrame(data1, index=pd.Index(['K0', 'K1', 'K2'], name='key')) index = pd.MultiIndex.from_tuples([('K0', 'Y0'), ('K1', 'Y1'), ('K2', 'Y2'), ('K2', 'Y3')], names=['key', 'Y']) df1 = pd.DataFrame(data2, index= index) print(df, "\n\n", df1) Output:
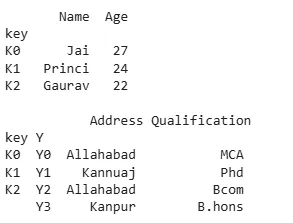 output
outputNow we join singly indexed dataframe with multi-indexed dataframe.
Python result = df.join(df1, how='inner') result
Output:
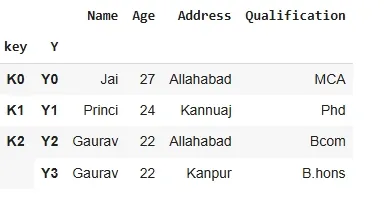 output
outputBy mastering the technique of concatenating, merging and joining DataFrames, we'll see the full potential of our data which makes it easier to manipulate, analyze and derive meaningful insights.
Similar Reads
Pandas Tutorial Pandas is an open-source software library designed for data manipulation and analysis. It provides data structures like series and DataFrames to easily clean, transform and analyze large datasets and integrates with other Python libraries, such as NumPy and Matplotlib. It offers functions for data t
6 min read
Introduction
Creating Objects
Viewing Data
Selection & Slicing
Dealing with Rows and Columns in Pandas DataFrameA Data frame is a two-dimensional data structure, i.e., data is aligned in a tabular fashion in rows and columns. We can perform basic operations on rows/columns like selecting, deleting, adding, and renaming. In this article, we are using nba.csv file. Dealing with Columns In order to deal with col
5 min read
Pandas Extracting rows using .loc[] - PythonPandas provide a unique method to retrieve rows from a Data frame. DataFrame.loc[] method is a method that takes only index labels and returns row or dataframe if the index label exists in the caller data frame. To download the CSV used in code, click here.Example: Extracting single Row In this exam
3 min read
Extracting rows using Pandas .iloc[] in PythonPython is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric Python packages. Pandas is one of those packages that makes importing and analyzing data much easier. here we are learning how to Extract rows using Pandas .iloc[] in Python.Pandas .iloc[
7 min read
Indexing and Selecting Data with PandasIndexing and selecting data helps us to efficiently retrieve specific rows, columns or subsets of data from a DataFrame. Whether we're filtering rows based on conditions, extracting particular columns or accessing data by labels or positions, mastering these techniques helps to work effectively with
4 min read
Boolean Indexing in PandasIn boolean indexing, we will select subsets of data based on the actual values of the data in the DataFrame and not on their row/column labels or integer locations. In boolean indexing, we use a boolean vector to filter the data. Boolean indexing is a type of indexing that uses actual values of the
6 min read
Python | Pandas DataFrame.ix[ ]Python's Pandas library is a powerful tool for data analysis, it provides DataFrame.ix[] method to select a subset of data using both label-based and integer-based indexing.Important Note: DataFrame.ix[] method has been deprecated since Pandas version 0.20.0 and is no longer recommended for use in n
2 min read
Python | Pandas Series.str.slice()Python is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric python packages. Pandas is one of those packages and makes importing and analyzing data much easier. Pandas str.slice() method is used to slice substrings from a string present in Pandas
3 min read
How to take column-slices of DataFrame in Pandas?In this article, we will learn how to slice a DataFrame column-wise in Python. DataFrame is a two-dimensional tabular data structure with labeled axes. i.e. columns.Creating Dataframe to slice columnsPython# importing pandas import pandas as pd # Using DataFrame() method from pandas module df1 = pd.
2 min read
Operations
Python | Pandas.apply()Pandas.apply allow the users to pass a function and apply it on every single value of the Pandas series. It comes as a huge improvement for the pandas library as this function helps to segregate data according to the conditions required due to which it is efficiently used in data science and machine
4 min read
Apply function to every row in a Pandas DataFramePython is a great language for performing data analysis tasks. It provides a huge amount of Classes and functions which help in analyzing and manipulating data more easily. In this article, we will see how we can apply a function to every row in a Pandas Dataframe. Apply Function to Every Row in a P
7 min read
Python | Pandas Series.apply()Pandas series is a One-dimensional ndarray with axis labels. The labels need not be unique but must be a hashable type. The object supports both integer- and label-based indexing and provides a host of methods for performing operations involving the index. Pandas Series.apply() function invoke the p
3 min read
Pandas dataframe.aggregate() | PythonDataframe.aggregate() function is used to apply some aggregation across one or more columns. Aggregate using callable, string, dict or list of string/callables. The most frequently used aggregations are:sum: Return the sum of the values for the requested axismin: Return the minimum of the values for
2 min read
Pandas DataFrame mean() MethodPython is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric Python packages. Pandas is one of those packages and makes importing and analyzing data much easier. Pandas DataFrame mean()Â Pandas dataframe.mean() function returns the mean of the value
2 min read
Python | Pandas Series.mean()Pandas series is a One-dimensional ndarray with axis labels. The labels need not be unique but must be a hashable type. The object supports both integer- and label-based indexing and provides a host of methods for performing operations involving the index. Pandas Series.mean() function return the me
2 min read
Python | Pandas dataframe.mad()Python is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric python packages. Pandas is one of those packages and makes importing and analyzing data much easier. Pandas dataframe.mad() function return the mean absolute deviation of the values for t
2 min read
Python | Pandas Series.mad() to calculate Mean Absolute Deviation of a SeriesPandas provide a method to make Calculation of MAD (Mean Absolute Deviation) very easy. MAD is defined as average distance between each value and mean. The formula used to calculate MAD is: Syntax: Series.mad(axis=None, skipna=None, level=None) Parameters: axis: 0 or ‘index’ for row wise operation a
2 min read
Python | Pandas dataframe.sem()Python is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric python packages. Pandas is one of those packages and makes importing and analyzing data much easier. Pandas dataframe.sem() function return unbiased standard error of the mean over reques
3 min read
Python | Pandas Series.value_counts()Pandas is one of the most widely used library for data handling and analysis. It simplifies many data manipulation tasks especially when working with tabular data. In this article, we'll explore the Series.value_counts() function in Pandas which helps you quickly count the frequency of unique values
2 min read
Pandas Index.value_counts()-PythonPython is popular for data analysis thanks to its powerful libraries and Pandas is one of the best. It makes working with data simple and efficient. The Index.value_counts() function in Pandas returns the count of each unique value in an Index, sorted in descending order so the most frequent item co
3 min read
Applying Lambda functions to Pandas DataframeIn Python Pandas, we have the freedom to add different functions whenever needed like lambda function, sort function, etc. We can apply a lambda function to both the columns and rows of the Pandas data frame.Syntax: lambda arguments: expressionAn anonymous function which we can pass in instantly wit
6 min read
Manipulating Data
Adding New Column to Existing DataFrame in PandasAdding a new column to a DataFrame in Pandas is a simple and common operation when working with data in Python. You can quickly create new columns by directly assigning values to them. Let's discuss how to add new columns to the existing DataFrame in Pandas. There can be multiple methods, based on d
6 min read
Python | Delete rows/columns from DataFrame using Pandas.drop()Python is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric Python packages. Pandas is one of those packages which makes importing and analyzing data much easier. In this article, we will how to delete a row in Excel using Pandas as well as delete
4 min read
Python | Pandas DataFrame.truncatePandas DataFrame is a two-dimensional size-mutable, potentially heterogeneous tabular data structure with labeled axes (rows and columns). Arithmetic operations align on both row and column labels. It can be thought of as a dict-like container for Series objects. This is the primary data structure o
3 min read
Python | Pandas Series.truncate()Pandas series is a One-dimensional ndarray with axis labels. The labels need not be unique but must be a hashable type. The object supports both integer- and label-based indexing and provides a host of methods for performing operations involving the index. Pandas Series.truncate() function is used t
2 min read
Iterating over rows and columns in Pandas DataFrameIteration is a general term for taking each item of something, one after another. Pandas DataFrame consists of rows and columns so, to iterate over dataframe, we have to iterate a dataframe like a dictionary. In a dictionary, we iterate over the keys of the object in the same way we have to iterate
7 min read
Pandas Dataframe.sort_values()In Pandas, sort_values() function sorts a DataFrame by one or more columns in ascending or descending order. This method is essential for organizing and analyzing large datasets effectively.Syntax: DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last')
2 min read
Python | Pandas Dataframe.sort_values() | Set-2Prerequisite: Pandas DataFrame.sort_values() | Set-1 Python is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric Python packages. Pandas is one of those packages, and makes importing and analyzing data much easier. Pandas sort_values() function so
3 min read
How to add one row in existing Pandas DataFrame?Adding rows to a Pandas DataFrame is a common task in data manipulation and can be achieved using methods like loc[], and concat(). Method 1. Using loc[] - By Specifying its Index and ValuesThe loc[] method is ideal for directly modifying an existing DataFrame, making it more memory-efficient compar
4 min read
Grouping Data
Merging, Joining, Concatenating and Comparing
Python | Pandas Merging, Joining and ConcatenatingPandas DataFrame helps for working with data organized in rows and columns. When we're working with multiple datasets we need to combine them in different ways. Pandas provides three simple methods like merging, joining and concatenating. These methods help us to combine data in various ways whether
9 min read
Python | Pandas Series.str.cat() to concatenate stringPython is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric python packages. Pandas is one of those packages and makes importing and analyzing data much easier.Pandas str.cat() is used to concatenate strings to the passed caller series of string.
3 min read
Python - Pandas dataframe.append()Pandas append function is used to add rows of other dataframes to end of existing dataframe, returning a new dataframe object. Columns not in the original data frames are added as new columns and the new cells are populated with NaN value.Append Dataframe into another DataframeIn this example, we ar
4 min read
Python | Pandas Series.append()Pandas series is a One-dimensional ndarray with axis labels. The labels need not be unique but must be a hashable type. The object supports both integer- and label-based indexing and provides a host of methods for performing operations involving the index. Pandas Series.append() function is used to
4 min read
Pandas Index.append() - PythonIndex.append() method in Pandas is used to concatenate or append one Index object with another Index or a list/tuple of Index objects, returning a new Index object. It does not modify the original Index. Example:Pythonimport pandas as pd idx1 = pd.Index([1, 2, 3]) idx2 = pd.Index([4, 5]) res = idx1.
2 min read
Python | Pandas Series.combine()Python is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric Python packages. Pandas is one of those packages and makes importing and analyzing data much easier. Pandas Series.combine() is a series mathematical operation method. This is used to com
3 min read
Add a row at top in pandas DataFramePandas DataFrame is two-dimensional size-mutable, potentially heterogeneous tabular data structure with labeled axes (rows and columns). Let's see how can we can add a row at top in pandas DataFrame.Observe this dataset first. Python3 # importing pandas module import pandas as pd # making data fram
1 min read
Python | Pandas str.join() to join string/list elements with passed delimiterPython is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric Python packages. Pandas is one of those packages and makes importing and analyzing data much easier. Pandas str.join() method is used to join all elements in list present in a series with
2 min read
Join two text columns into a single column in PandasLet's see the different methods to join two text columns into a single column. Method #1: Using cat() function We can also use different separators during join. e.g. -, _, " " etc. Python3 1== # importing pandas import pandas as pd df = pd.DataFrame({'Last': ['Gaitonde', 'Singh', 'Mathur'], 'First':
2 min read
How To Compare Two Dataframes with Pandas compare?A DataFrame is a 2D structure composed of rows and columns, and where data is stored into a tubular form. It is mutable in terms of size, and heterogeneous tabular data. Arithmetic operations can also be performed on both row and column labels. To know more about the creation of Pandas DataFrame. He
5 min read
How to compare the elements of the two Pandas Series?Sometimes we need to compare pandas series to perform some comparative analysis. It is possible to compare two pandas Series with help of Relational operators, we can easily compare the corresponding elements of two series at a time. The result will be displayed in form of True or False. And we can
3 min read
Working with Date and Time
Python | Working with date and time using PandasWhile working with data, encountering time series data is very usual. Pandas is a very useful tool while working with time series data. Pandas provide a different set of tools using which we can perform all the necessary tasks on date-time data. Let's try to understand with the examples discussed b
8 min read
Python | Pandas Timestamp.timestampPython is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric Python packages. Pandas is one of those packages and makes importing and analyzing data much easier. Pandas Timestamp.timestamp() function returns the time expressed as the number of seco
3 min read
Python | Pandas Timestamp.nowPython is a great language for data analysis, primarily because of the fantastic ecosystem of data-centric Python packages. Pandas is one of those packages that makes importing and analyzing data much easier. Pandas Timestamp.now() function returns the current time in the local timezone. It is Equiv
3 min read
Python | Pandas Timestamp.isoformatPython is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric Python packages. Pandas is one of those packages and makes importing and analyzing data much easier. Pandas Timestamp objects represent date and time values, making them essential for wor
2 min read
Python | Pandas Timestamp.datePython is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric python packages. Pandas is one of those packages and makes importing and analyzing data much easier. Pandas Timestamp.date() function return a datetime object with same year, month and da
2 min read
Python | Pandas Timestamp.replacePython is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric Python packages. Pandas is one of those packages that makes importing and analyzing data much easier. Pandas Timestamp.replace() function is used to replace the member values of the given
3 min read
Pandas.to_datetime()-Pythonpandas.to_datetime() converts argument(s) to datetime. This function is essential for working with date and time data, especially when parsing strings or timestamps into Python's datetime64 format used in Pandas. For Example:Pythonimport pandas as pd d = ['2025-06-21', '2025-06-22'] res = pd.to_date
3 min read
Python | pandas.date_range() methodPython is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric Python packages. Pandas is one of those packages that makes importing and analyzing data much easier. pandas.date_range() is one of the general functions in Pandas which is used to return
4 min read