Relationship Extraction in NLP
Last Updated : 28 Apr, 2025
Relationship extraction in natural language processing (NLP) is a technique that helps understand the connections between entities mentioned in text. In a world brimming with unstructured textual data, relationship extraction is an effective technique for organizing information, constructing knowledge graphs, aiding information retrieval, and supporting decision-making processes by identifying and classifying the associations between entities.
The main goal of relationship extraction is to extract valuable insights from text that enrich our understanding of the relationships that bind people, organizations, concepts, etc.
What is Relationship Extraction in NLP?
Relationship Extraction (RE) is an important process in Natural Language Processing that automatically identifies and categorizes the connections between entities within natural language text. These entities can encompass individuals, organizations, locations, dates, or any other nouns or concepts mentioned in the text. The relationships denote how these entities are related to each other, like "founder of", "located in", "works at" "married to", etc. For instance, "John works at the company" illustrates a "works at" relationship from John to the company. This extracted relationship serves to enrich the semantic understanding of the text and can be organized into structured data for various downstream applications.
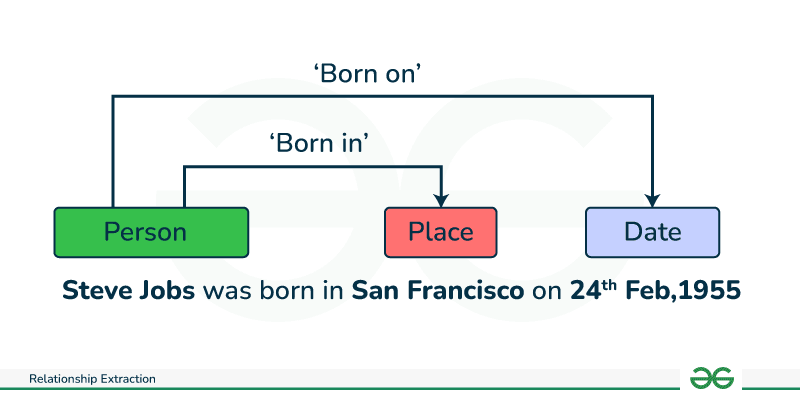
Approaches of Extracting Relationships in NLP
1. Rule Based or Pattern Based Approach
- Rule based relationship extraction define rules based on syntactic or semantic structures in text to identify relationships.
- In this grammatical structure of sentence is analyzed to identify dependencies between words.
- Relationships can be inferred based on the syntactic relationships between the entities.
2. Supervised Relationship Extraction
- In a supervised learning framework for relation extraction, the task is treated as a classification problem. The process involves annotating a training corpus with both entities and their corresponding relations. The focus is on identifying pairs of named entities, typically found within the same sentence. Following this, a relation classification step is applied to each entity pair.
- For the classification task, a diverse set of supervised techniques can be employed, ranging from traditional methods like logistic regression and random forest to more advanced models such as recurrent neural networks (RNNs), transformers, or neural classifiers. The primary objective is to leverage the annotated texts in the training corpus to teach the classifier to recognize and categorize relationships between pairs of named entities.
3. Unsupervised Relationship Extraction
- Unsupervised relation extraction, often referred to as Open Information Extraction (Open IE), aims to identify relationships in text without the availability of labeled training data or predefined lists of relations. In Open IE, relations are represented as strings of words, typically starting with a verb. The objective is to extract these relationships directly from the text without relying on prior knowledge or annotated examples.
Types of Relationship Extraction in NLP
We can categorize relational extraction into various types, which are listed below:
Binary Relationship Extraction
- This extraction process focuses on identifying and categorizing relationships between pairs of entities, which is a fundamental form of relationship extraction and is often used when the relationships are simple and can be expressed as pairs.
- For example, determining whether a person "founded" an organization (Sandeep Jain founded GeeksforGeeks)
- The process of binary relationship extraction involves the following steps:
- Named entity recognition is performed to identify and classify entities in the test. Entities can be people, locations or any other relevant nouns in the context.
- To analyze the grammatical structure of the text and understand the relationship between words dependency parsing is used.
- The model determines the relationship between two identified entities by examining the context and co-occurrence of the entities in the text.
- If a relationship is identified, it is often classified into a specific type or category. For example, if the entities are a person and an organization, the relationship might be categorized as "works for."
- The final step extracts the binary relationships from the text and store them in a structured format.
Ternary Relationship Extraction
- Ternary relationship extraction is an advanced natural language processing (NLP) task that extends the concept of binary relationship extraction by identifying and extracting relationships involving three entities from unstructured text data. This task is essential for constructing more complex knowledge graphs and extracting nuanced information from text.
Nested Relationship Extraction
- This extraction process is used when relationships within a text are hierarchical or embedded within one another.
- For example, in a sentence like "Sandeep Jain, the CEO of GeeksforGeeks, founded the company," there are nested relationships involving Sandeep Jain, GeeksforGeeks and the "founded" relationship.
- The process is quite similar to ternary and binary relationship extraction.
- The process begins with name entity recognition.
- The dependency parsing is employed to analyze the grammatical structure of the text.
- The primary focus of nested relationship extraction is to identify and extract hierarchical or nested relationships between entities. This involves determining how entities are hierarchically structured and how they relate to each other. For example, you might want to extract relationships like "is part of," "contains," "is a member of," and so on.
- Once these nested relationships are identified, they are often classified into specific types or categories. This categorization helps in understanding the nature of the hierarchical relationships among the entities. For instance, if you're extracting relationships between parts of a machine, you might classify them as "subcomponent," "component," or "assembly."
- The final step is to extract the nested relationships from the text and represent them in a structured format.
Temporal Relationship Extraction
- This extraction focuses on identifying relationships with a temporal dimension which includes determining when an event occurred or when a relationship was valid.
- Temporal relationships are essential for understanding the chronological order, duration, and temporal dependencies between events.
- For example, "GeeksforGeeks was founded by Sandeep Jain in 2008".
- The process of temporal relationship extraction involves following step:
- Temporal relationship extraction involves recognizing and identifying events, actions, or entities mentioned in the text.
- In parallel, the system needs to identify and classify temporal expressions within the text. Temporal expressions can be specific dates, times, durations, or more complex phrases like "two weeks ago" or "in the future."
- Dependency parsing is often used to analyze the grammatical structure of the text, enabling the understanding of how different elements in the text are connected, including how temporal expressions relate to events or entities.
- The core task of temporal relationship extraction involves identifying the temporal relationships between events or entities and the associated temporal expressions.
- Once the temporal relationships are identified, they are typically categorized into specific types or classes. These classes can include "before," "after," "during," "simultaneous," "started," "ended," and more, depending on the nuances of the temporal relationships.
- The final step is to extract and represent these temporal relationships in a structured format, such as a timeline or a knowledge graph.
Casual Relationship Extraction
- This extraction identifies relationships that express cause and effect which is crucial in applications like identifying the causes of diseases or understanding the reasons behind certain events.
- The process of causal relationship extraction is to determine if a causal relationship exists between the identified events or entities.
- This requires examining the context and linguistic cues in the text to identify whether one event or entity is causing another, or if there is a correlation between them.
- Once a causal relationship is identified, it can be further classified into specific types or categories.
- For instance, causal relationships can be categorized as direct causation, indirect causation, correlation, reverse causation, or temporal causation.
- The final step is to extract and represent the causal relationships in a structured format, such as a causal graph or knowledge base.
Cross-Sentence Relationship Extraction
- When relationships span multiple sentences, Cross-sentence relationship extraction is used to identify and extract relationships that exist across sentence boundaries, often requiring coreference resolution and contextual analysis.
- The process involves:
- Cross-sentence relationship extraction is to identify and extract relationships between entities or events that are mentioned in different sentences. This can involve recognizing how actions or entities mentioned in one sentence relate to those in another, such as causality, dependency, or association.
- Once the relationships are identified, they can be categorized into specific types or classes. The classification helps in understanding the nature of the relationships that span multiple sentences, such as causal relationships, temporal dependencies, or co-occurrence.
Open Information Extraction (OpenIE)
- In this special extraction process, relationships between entities are extracted based on the grammatical dependencies and patterns in the text without relying on predefined schemas or categories which allows it to capture a wide range of relationships.
- Key features of Open Information Extraction include:
- OpenIE systems are designed to discover relations between entities mentioned in text. These relations can be explicit, such as "X works for Y," or implicit, such as "X is an instance of Y." OpenIE systems aim to uncover a wide variety of relationships, not limited to a predefined set.
- To extract relations, OpenIE systems also need to identify entities (e.g., people, organizations, locations) within the text.
- OpenIE does not require prior knowledge of the specific relations to be extracted. It can discover novel relations that were not anticipated in advance.
- OpenIE systems are designed to scale to large corpora and can extract information from extensive textual datasets.
In this article, we will see how to perform Relationship extraction from a set of text.
Step-by-step implementation
Installing required modules
We will need to install Transformers module for named entity recognition (NER) using the BERT model and spaCy module for natural language processing in our runtime. Then we will install a small English model of spaCy called 'en_core_web_sm' which is used for various NLP tasks like tokenization and dependency parsing.
!pip install spacy-transformers
!python -m spacy download en_core_web_sm
Importing module
Now we will import all required modules like pipeline etc.
Python3 import spacy from transformers import pipeline
Loading spaCy model
To use the spacy model, It should downloaded in your system.
Next we will load the English model of spaCy for text processing.
Python3 # Load spaCy's transformer-based model nlp = spacy.load("en_core_web_sm") Text processing
We will consider any sample text as per our choices. Then we will perform text process using the spaCy model which is loaded in the previous code.
Python3 # Define a sample text for relationship extraction text = "GeekforGeeks was founded by Sandeep Jain. Sandeep Jain was a former teacher. GeeksforGeeks is a computer science portal and offers various cources and articles." # Process the text with spaCy doc = nlp(text) # Create a list to store extracted relationships relationships = []
Fine-tune model for named entity recognition
We will use a fine-tuned model for Named Entity Recognition which can be loaded by transformers pipeline. This model will be used to extract the named entities from the text.
Python3 # Use Hugging Face's transformers NER pipeline for named entity recognition nlp_ner = pipeline("ner", model="dbmdz/bert-large-cased-finetuned-conll03-english") # Extract named entities and their labels named_entities = nlp_ner(text) Checking Entity Labels and Extracting Relationships
Now we will iterate the model through the set of sentences and check if there is an entity with a known labels like person or org etc. Then we will check the grammatical dependencies to extract relationships.
Python3 # Iterate through the sentences in the document for sent in doc.sents: # Iterate through the named entities (people, organizations etc.) in the sentence for ent in sent.ents: # Check if the entity has a known label and is a person or organization if ent.label_ in ["PERSON", "ORG"]: # Extract the relationship for token in sent: if token.dep_ in ["attr", "nsubj", "dobj"]: relationships.append((ent.text, token.text))
Printing extracted relationships
Finally, we will print the relationships with the corresponding named entities.
Python3 for named_entities, relation in relationships: print(f"{named_entities} --> {relation}") Output:
Sandeep Jain --> Jain
Sandeep Jain --> teacher
GeeksforGeeks --> GeeksforGeeks
GeeksforGeeks --> portal
GeeksforGeeks --> cources
Conclusion
We can conclude that, relation extraction is an important task in NLP and can be done by using various models. Our approach gives a desired output by covering Open Information extraction and Binary extraction techniques. However, an un-usual output, 'GeeksforGeeks->GeeksforGeeks' is generated which shows that there is more requirement of fine-tuning. Here, we have used already available fine-tuned model, but we can also perform manual fine-tuning, or another available fine-tuned model can be used as per requirement.
Similar Reads
Information Extraction in NLP Information Extraction (IE) in Natural Language Processing (NLP) is a crucial technology that aims to automatically extract structured information from unstructured text. This process involves identifying and pulling out specific pieces of data, such as names, dates, relationships, and more, to tran
6 min read
Create Relationship in MongoDB In MongoDB, managing relationships between data is crucial for structuring and querying databases effectively. Relationships can be handled using embedded documents, references and the $lookup aggregation stage, each offering different advantages depending on the use case.In this article, We will le
7 min read
One-To-Many Relationship Example One-To-Many Relationship signifies connection between two entities where one entity is associated with multiple instances of the other entity but each instance of second entity is associated with only one instance of first entity. Depending on how we look at it, a one-to-many relationship is also ca
5 min read
Types of Relationship in Database A relationship in a DBMS exists when a variable has a connection with the properties stored in different tables. Such relationships help the organization of entities intertwined with each other, ultimately enabling efficient data processing. They're exhibited usually via keys in a table, which is ei
4 min read
Feature Extraction Techniques - NLP Introduction : This article focuses on basic feature extraction techniques in NLP to analyse the similarities between pieces of text. Natural Language Processing (NLP) is a branch of computer science and machine learning that deals with training computers to process a large amount of human (natural)
10 min read