Frequent Pattern Growth Algorithm
Last Updated : 27 May, 2025
The FP-Growth (Frequent Pattern Growth) algorithm efficiently mines frequent itemsets from large transactional datasets. Unlike the Apriori algorithm which suffers from high computational cost due to candidate generation and multiple database scans. FP-Growth avoids these inefficiencies by compressing the data into an FP-Tree (Frequent Pattern Tree) and extracts patterns directly from it.
How FP-Growth Works
Here's how it works in simple terms:
- Data Compression: First FP-Growth compresses the dataset into a smaller structure called the Frequent Pattern Tree (FP-Tree). This tree stores information about item sets (collections of items) and their frequencies without need to generate candidate sets like Apriori does.
- Mining the Tree: The algorithm then examines this tree to identify patterns that appear frequently based on a minimum support threshold. It does this by breaking the tree down into smaller "conditional" trees for each item making the process more efficient.
- Generating Patterns: Once the tree is built and analyzed the algorithm generates the frequent patterns (itemsets) and the rules that describe relationships between items.
Imagine you’re organizing a party and want to know popular food combinations without asking every guest repeatedly.
- List food items each guest brought transactions.
- Count items and remove infrequent ones filter by support.
- Group items in order of popularity and create a tree where paths represent common combinations.
- Instead of repeatedly asking guests you explore this tree to discover patterns. For example, you might find that pizza and pasta often come together or that cake and pasta are also a common pair.
This is exactly how FP-Growth finds frequent patterns efficiently.
Working of FP- Growth Algorithm
Lets jump to the usage of FP- Growth Algorithm and how it works with reallife data. Consider the following data:
Transaction ID | Items |
|---|
T1 | {E,K,M,N,O,Y} |
|---|
T2 | {D,E,K,N,O,Y} |
|---|
T3 | {A,E,K,M} |
|---|
T4 | {K,M,Y} |
|---|
T5 | {C,E,I,K,O,O} |
|---|
The above-given data is a hypothetical dataset of transactions with each letter representing an item. The frequency of each individual item is computed:-
Item | Frequency |
|---|
A | 1 |
|---|
C | 2 |
|---|
D | 1 |
|---|
E | 4 |
|---|
I | 1 |
|---|
K | 5 |
|---|
M | 3 |
|---|
N | 2 |
|---|
O | 4 |
|---|
U | 1 |
|---|
Y | 3 |
|---|
Let the minimum support be 3. A Frequent Pattern set is built which will contain all the elements whose frequency is greater than or equal to the minimum support. These elements are stored in descending order of their respective frequencies. After insertion of the relevant items, the set L looks like this:-
L = {K : 5, E : 4, M : 3, O : 4, Y : 3}
Now for each transaction the respective Ordered-Item set is built. It is done by iterating the Frequent Pattern set and checking if the current item is contained in the transaction in question. If the current item is contained the item is inserted in the Ordered-Item set for the current transaction. The following table is built for all the transactions:
Transaction ID | Items | Ordered-Item-Set |
|---|
T1 | {E,K,M,N,O,Y} | {K,E,M,O,Y} |
|---|
T2 | {D,E,K,N,O,Y} | {K,E,O,Y} |
|---|
T3 | {A,E,K,M} | {K,E,M} |
|---|
T4 | {C,K,M,U,Y} | {K,M,Y} |
|---|
T5 | {C,E,I,K,O,O} | {K,E,O} |
|---|
Now all the Ordered-Item sets are inserted into a Tree Data Structure.
a) Inserting the set {K, E, M, O, Y}
Here all the items are simply linked one after the other in the order of occurrence in the set and initialise the support count for each item as 1. For inserting {K, E, M, O, Y} we traverse the tree from the root. If a node already exists for an item, we increase its support count. If it doesn’t exist, we create a new node for that item and link it to the previous item.
 Inserting the set {K, E, M, O, Y}
Inserting the set {K, E, M, O, Y}b) Inserting the set {K, E, O, Y}
Till the insertion of the elements K and E, simply the support count is increased by 1. On inserting O we can see that there is no direct link between E and O, therefore a new node for the item O is initialized with the support count as 1 and item E is linked to this new node. On inserting Y, we first initialize a new node for the item Y with support count as 1 and link the new node of O with the new node of Y.
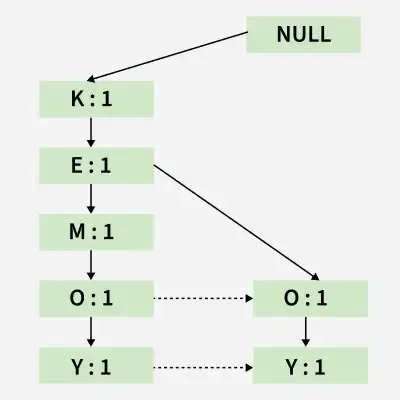 Inserting the set {K, E, O, Y}
Inserting the set {K, E, O, Y}c) Inserting the set {K, E, M}
Here simply the support count of each element is increased by 1.
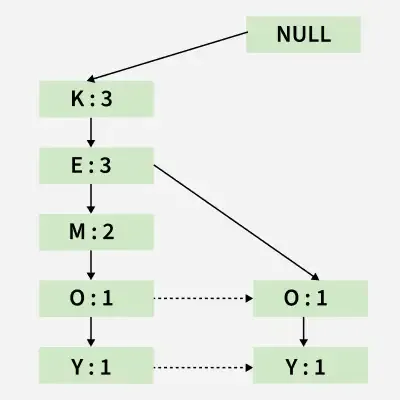 Inserting the set {K, E, M}
Inserting the set {K, E, M}d) Inserting the set {K, M, Y}
Similar to step b), first the support count of K is increased, then new nodes for M and Y are initialized and linked accordingly.
 Inserting the set {K, M, Y}
Inserting the set {K, M, Y}
e) Inserting the set {K, E, O}
Here simply the support counts of the respective elements are increased. Note that the support count of the new node of item O is increased.
 Inserting the set {K, E, O}
Inserting the set {K, E, O}The Conditional Pattern Base for each item consists of the set of prefixes of all paths in the FP-tree that lead to that item. Note that the items in the below table are arranged in the ascending order of their frequencies.

Now for each item, the Conditional Frequent Pattern Tree is built. It is done by taking the set of elements that is common in all the paths in the Conditional Pattern Base of that item and calculating its support count by summing the support counts of all the paths in the Conditional Pattern Base.

From the Conditional Frequent Pattern tree the Frequent Pattern rules are generated by pairing the items of the Conditional Frequent Pattern Tree set to the corresponding to the item as given in the below table.

For each row two types of association rules can be inferred for example for the first row which contains the element, the rules K -> Y and Y -> K can be inferred. To determine the valid rule, the confidence of both the rules is calculated and the one with confidence greater than or equal to the minimum confidence value is retained.
Frequent Pattern Growth (FP-Growth) algorithm improves upon the Apriori algorithm by eliminating the need for multiple database scans and reducing computational overhead. By using a Tree data structure and focusing on ordered-item sets it efficiently mines frequent item sets making it a faster and more scalable solution for large datasets making it useful tool for data mining.
Similar Reads
Machine Learning Algorithms Machine learning algorithms are essentially sets of instructions that allow computers to learn from data, make predictions, and improve their performance over time without being explicitly programmed. Machine learning algorithms are broadly categorized into three types: Supervised Learning: Algorith
8 min read
Top 15 Machine Learning Algorithms Every Data Scientist Should Know in 2025 Machine Learning (ML) Algorithms are the backbone of everything from Netflix recommendations to fraud detection in financial institutions. These algorithms form the core of intelligent systems, empowering organizations to analyze patterns, predict outcomes, and automate decision-making processes. Wi
14 min read
Linear Model Regression
Ordinary Least Squares (OLS) using statsmodelsOrdinary Least Squares (OLS) is a widely used statistical method for estimating the parameters of a linear regression model. It minimizes the sum of squared residuals between observed and predicted values. In this article we will learn how to implement Ordinary Least Squares (OLS) regression using P
3 min read
Linear Regression (Python Implementation)Linear regression is a statistical method that is used to predict a continuous dependent variable i.e target variable based on one or more independent variables. This technique assumes a linear relationship between the dependent and independent variables which means the dependent variable changes pr
14 min read
Multiple Linear Regression using Python - MLLinear regression is a statistical method used for predictive analysis. It models the relationship between a dependent variable and a single independent variable by fitting a linear equation to the data. Multiple Linear Regression extends this concept by modelling the relationship between a dependen
4 min read
Polynomial Regression ( From Scratch using Python )Prerequisites Linear RegressionGradient DescentIntroductionLinear Regression finds the correlation between the dependent variable ( or target variable ) and independent variables ( or features ). In short, it is a linear model to fit the data linearly. But it fails to fit and catch the pattern in no
5 min read
Bayesian Linear RegressionLinear regression is based on the assumption that the underlying data is normally distributed and that all relevant predictor variables have a linear relationship with the outcome. But In the real world, this is not always possible, it will follows these assumptions, Bayesian regression could be the
10 min read
How to Perform Quantile Regression in PythonIn this article, we are going to see how to perform quantile regression in Python. Linear regression is defined as the statistical method that constructs a relationship between a dependent variable and an independent variable as per the given set of variables. While performing linear regression we a
4 min read
Isotonic Regression in Scikit LearnIsotonic regression is a regression technique in which the predictor variable is monotonically related to the target variable. This means that as the value of the predictor variable increases, the value of the target variable either increases or decreases in a consistent, non-oscillating manner. Mat
6 min read
Stepwise Regression in PythonStepwise regression is a method of fitting a regression model by iteratively adding or removing variables. It is used to build a model that is accurate and parsimonious, meaning that it has the smallest number of variables that can explain the data. There are two main types of stepwise regression: F
6 min read
Least Angle Regression (LARS)Regression is a supervised machine learning task that can predict continuous values (real numbers), as compared to classification, that can predict categorical or discrete values. Before we begin, if you are a beginner, I highly recommend this article. Least Angle Regression (LARS) is an algorithm u
3 min read
Linear Model Classification
Regularization
K-Nearest Neighbors (KNN)
Support Vector Machines
ML - Stochastic Gradient Descent (SGD) Stochastic Gradient Descent (SGD) is an optimization algorithm in machine learning, particularly when dealing with large datasets. It is a variant of the traditional gradient descent algorithm but offers several advantages in terms of efficiency and scalability, making it the go-to method for many d
8 min read
Decision Tree
Ensemble Learning