What is Bagging classifier?
Last Updated : 15 May, 2025
Ensemble learning is a supervised machine-learning technique that combines multiple models to build reliable models and prediction accurate model. It works by combining the strengths of multiple model to create a model that is robust and less likely to overfit the data.
Bagging Classifier
Bagging or Bootstrap aggregating is a type of ensemble learning in which multiple base models are trained independently and parallelly on different subsets of training data. Each subset is generated using bootstrap sampling in which data points are picked at randomly with replacement. In bagging classifier the final prediction is made by aggregating the predictions of all base model using majority voting. In the models of regression the final prediction is made by averaging the predictions of the all base model and that is known as bagging regression.
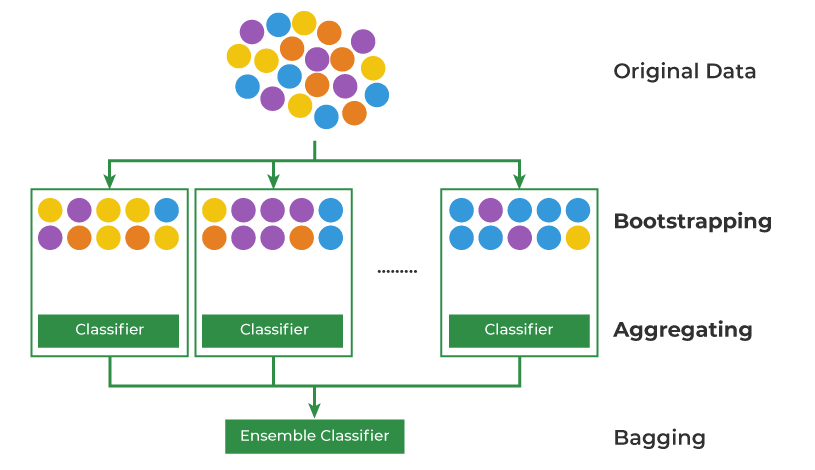 Bagging Classifier
Bagging ClassifierStarting with an original dataset containing multiple data points (represented by colored circles). The original dataset is randomly sampled with replacement multiple times. This means that in each sample, a data point can be selected more than once or not at all. These samples create multiple subsets of the original data.
- For each of the bootstrapped subsets, a separate classifier (e.g., decision tree, logistic regression) is trained.
- The predictions from all the individual classifiers are combined to form a final prediction. This is often done through a majority vote (for classification) or averaging (for regression).
Bagging helps improve accuracy and reduce overfitting especially in models that have high variance.
How does Bagging Classifier Work?
- Bootstrap Sampling: In Bootstrap Sampling data are sampled with 'n' subsets are made randomly from original training dataset with replacement. This step ensures that the base models are trained on diverse subsets of the data as some samples may appear multiple times in the new subset while others may be left out. It reduces the risks of overfitting and improves the accuracy of the model.
Let's break it down step by step:
Original training dataset: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
Resampled training set 1: [2, 3, 3, 5, 6, 1, 8, 10, 9, 1]
Resampled training set 2: [1, 1, 5, 6, 3, 8, 9, 10, 2, 7]
Resampled training set 3: [1, 5, 8, 9, 2, 10, 9, 7, 5, 4]
- Base Model Training: In bagging multiple base models are used. After the Bootstrap Sampling each base model is independently trained using learning algorithm such as decision trees, support vector machines or neural networks on a different bootstrapped subset data. These models are typically called "Weak learners" because they are not highly accurate. Since the base model is trained independently and parallelly it makes it computationally efficient and time saving.
- Aggregation: Once all the base models are trained and makes predictions on new unseen data then bagging classifier predicts class label for given instance by majority voting from all base learners. The class which has the majority voting is the prediction of the model.
- Out-of-Bag (OOB) Evaluation: Some samples are excluded from the training subset of particular base models during the bootstrapping method. These "out-of-bag" samples can be used to estimate the model's performance without the need for cross-validation.
Bagging Classifier process begins with the original training dataset which is used to create bootstrap samples (random subsets with replacement) for training multiple weak learners ensuring diversity. Each weak learner independently predicts outcomes as shown in the Base Model Training graph capturing different patterns. These predictions are aggregated using majority voting where the final classification is determined by the maximum voted output. The Out-of-Bag (OOB) evaluates models performance on data excluded from each bootstrap sample for validation. This approach enhances accuracy and reduces overfitting.
Python implementation of the Bagging classifier algorithm
Step 1: Define the Bagging Classifier class with the base_classifier and n_estimators as input parameters for the constructor. Initialize the class attributes base_classifier, n_estimators, and an empty list classifiers to store the trained classifiers.
Step 2: Define the fit method to train the bagging classifiers:
For each iteration from 0 to n_estimators - 1:
- Perform bootstrap sampling with replacement by randomly selecting len(X) indices from the range of len(X) with replacement.
- Create new subsets X_sampled and y_sampled by using the selected indices.
- Create a new instance of the base_classifier to create a new classifier model for this iteration.
- Train the classifier on the sampled data X_sampled and y_sampled.
- Append the trained classifier to the list classifiers.
- Return the list of trained classifiers.
Step 3: Define the predict method to make predictions using the ensemble of classifiers:
- For each classifier in the classifiers list:
- Use the trained classifier to predict the classes of the input data X.
- Aggregate the predictions using majority voting to get the final predictions.
- Return the final predictions.
Python class BaggingClassifier: def __init__(self, base_classifier, n_estimators): self.base_classifier = base_classifier self.n_estimators = n_estimators self.classifiers = [] def fit(self, X, y): for _ in range(self.n_estimators): # Bootstrap sampling with replacement indices = np.random.choice(len(X), len(X), replace=True) X_sampled = X[indices] y_sampled = y[indices] # Create a new base classifier and train it on the sampled data classifier = self.base_classifier.__class__() classifier.fit(X_sampled, y_sampled) # Store the trained classifier in the list of classifiers self.classifiers.append(classifier) return self.classifiers def predict(self, X): # Make predictions using all the base classifiers predictions = [classifier.predict(X) for classifier in self.classifiers] # Aggregate predictions using majority voting majority_votes = np.apply_along_axis(lambda x: np.bincount(x).argmax(), axis=0, arr=predictions) return majority_votes
Importing Necessary Libraries
Python from sklearn.datasets import load_digits from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.tree import DecisionTreeClassifier
Load the dataset
Python # Load the dataset digit = load_digits() X, y = digit.data, digit.target # Split the data into training and testing sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Create the base classifier dc = DecisionTreeClassifier() model = BaggingClassifier(base_classifier=dc, n_estimators=10) classifiers = model.fit(X_train, y_train) # Make predictions on the test set y_pred = model.predict(X_test) # Calculate accuracy accuracy = accuracy_score(y_test, y_pred) print("Accuracy:", accuracy) Output:
Accuracy: 0.9472222222222222
Let's check the result of each classifier individually
Python for i, clf in enumerate(classifiers): y_pred = clf.predict(X_test) # Calculate accuracy accuracy = accuracy_score(y_test, y_pred) print("Accuracy:"+str(i+1),':', accuracy) Output:
Accuracy:1 : 0.8833333333333333
Accuracy:2 : 0.8361111111111111
Accuracy:3 : 0.85
Accuracy:4 : 0.85
Accuracy:5 : 0.8388888888888889
Accuracy:6 : 0.8388888888888889
Accuracy:7 : 0.8472222222222222
Accuracy:8 : 0.8222222222222222
Accuracy:9 : 0.8527777777777777
Accuracy:10 : 0.8111111111111111
Advantages of Bagging Classifier
- Improved Predictive Performance: It outperforms single classifiers by reducing overfitting and increasing predictive accuracy by combining multiple base models.
- Robustness: Reduces the impact of outliers and noise in data by aggregating predictions from multiple models. This enhances the overall stability and robustness of the model.
- Reduced Variance: Since each base model is trained on different subsets of the data the aggregated model's variance is significantly reduced compared to individual model.
- Parallel Working: Bagging allows parallel processing as each base model can be trained independently in parallel. This makes it computationally efficient for large datasets.
- Flexibility: It can be applied to wide range of machine learning algorithms such as decision trees, random forests and support vector machines.
Disadvantages of Bagging:
- Loss of Interpretability: It involves aggregating predictions from multiple models making it harder to interpret individual base model.
- Computationally Expensive: As the number of iterations of bootstrap samples increases, computational cost of bagging also increase.
Applications of Bagging Classifier
- Fraud Detection: It can be used to detect fraudulent transactions by aggregating predictions from multiple fraud detection models.
- Spam filtering: It can be used to filter spam emails by aggregating predictions from multiple spam filters trained on different subsets of the spam emails.
- Credit scoring: Can be used to improve the accuracy of credit scoring models by combining multiple models.
- Image Classification: It can be used to improve the accuracy of image classification task.
- Natural language processing: In NLP tasks it can combine predictions from multiple language models to achieve better text classification results.
Bagging Classifier is a ensemble learning technique that improve model prediction and robustness. It helps avoiding overfitting, improves generalization and gives better predictions by using combining multiple base models and can be used for wide range of applications.