Gated Recurrent Unit Networks
Last Updated : 04 Jun, 2025
In machine learning Recurrent Neural Networks (RNNs) are essential for tasks involving sequential data such as text, speech and time-series analysis. While traditional RNNs struggle with capturing long-term dependencies due to the vanishing gradient problem architectures like Long Short-Term Memory (LSTM) networks were developed to overcome this limitation.
However LSTMs are very complex structure with higher computational cost. To overcome this Gated Recurrent Unit (GRU) where introduced which uses LSTM architecture by merging its gating mechanisms offering a more efficient solution for many sequential tasks without sacrificing performance. In this article we'll learn more about them.
What are Gated Recurrent Units (GRU) ?
Gated Recurrent Units (GRUs) are a type of RNN introduced by Cho et al. in 2014. The core idea behind GRUs is to use gating mechanisms to selectively update the hidden state at each time step allowing them to remember important information while discarding irrelevant details. GRUs aim to simplify the LSTM architecture by merging some of its components and focusing on just two main gates: the update gate and the reset gate.
 Structure of GRUs
Structure of GRUsThe GRU consists of two main gates:
- Update Gate (z_t): This gate decides how much information from previous hidden state should be retained for the next time step.
- Reset Gate (r_t): This gate determines how much of the past hidden state should be forgotten.
These gates allow GRU to control the flow of information in a more efficient manner compared to traditional RNNs which solely rely on hidden state.
Equations for GRU Operations
The internal workings of a GRU can be described using following equations:
1. Reset gate:
r_t = \sigma \left( W_r \cdot [h_{t-1}, x_t] \right)
The reset gate determines how much of the previous hidden state h_{t-1} should be forgotten.
2. Update gate:
z_t = \sigma(W_z \cdot [h_{t-1}, x_t])
The update gate controls how much of the new information x_t should be used to update the hidden state.
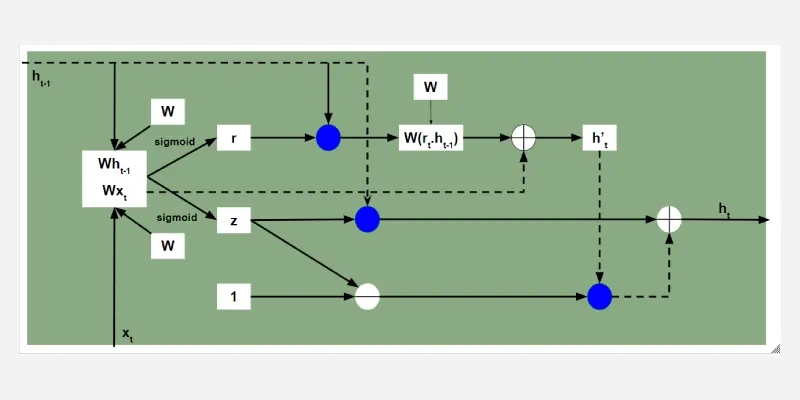 Architecture of GRUs
Architecture of GRUs3. Candidate hidden state:
h_t' = \tanh(W_h \cdot [r_t \cdot h_{t-1}, x_t])
This is the potential new hidden state calculated based on the current input and the previous hidden state.
4. Hidden state:
h_t = (1 - z_t) \cdot h_{t-1} + z_t \cdot h_t'
The final hidden state is a weighted average of the previous hidden state h_{t-1} and the candidate hidden state h_t' based on the update gate z_t.
How GRUs Solve the Vanishing Gradient Problem
Like LSTMs, GRUs were designed to address the vanishing gradient problem which is common in traditional RNNs. GRUs help mitigate this issue by using gates that regulate the flow of gradients during training ensuring that important information is preserved and that gradients do not shrink excessively over time. By using these gates, GRUs maintain a balance between remembering important past information and learning new, relevant data.
GRU vs LSTM
GRUs are more computationally efficient because they combine the forget and input gates into a single update gate. GRUs do not maintain an internal cell state as LSTMs do, instead they store information directly in the hidden state making them simpler and faster.
| Feature | LSTM (Long Short-Term Memory) | GRU (Gated Recurrent Unit) |
|---|
| Gates | 3 (Input, Forget, Output) | 2 (Update, Reset) |
|---|
| Cell State | Yes it has cell state | No (Hidden state only) |
|---|
| Training Speed | Slower due to complexity | Faster due to simpler architecture |
|---|
| Computational Load | Higher due to more gates and parameters | Lower due to fewer gates and parameters |
|---|
| Performance | Often better in tasks requiring long-term memory | Performs similarly in many tasks with less complexity |
|---|
Implementation in Python
Now let's implement simple GRU model in Python using Keras. We'll start by preparing the necessary libraries and dataset.
1. Importing Libraries
We will import the following libraries for implementing our GRU model.
- numpy: For handling numerical data and array manipulations.
- pandas: For data manipulation and reading datasets (CSV files).
- MinMaxScaler: For normalizing the dataset.
- TensorFlow: For building and training the GRU model.
- Adam: An optimization algorithm used during training.
Python import numpy as np import pandas as pd from sklearn.preprocessing import MinMaxScaler from tensorflow.keras.models import Sequential from tensorflow.keras.layers import GRU, Dense from tensorflow.keras.optimizers import Adam
2. Loading the Dataset
The dataset we're using is a time-series dataset containing daily temperature data i.e forecasting dataset. It spans 8,000 days starting from January 1, 2010. You can download dataset from here.
- pd.read_csv(): Reads a CSV file into a pandas DataFrame. Here, we are assuming that the dataset has a Date column which is set as the index of the DataFrame.
- date_parser=True: Ensures that pandas parses the 'Date' column as datetime.
Python df = pd.read_csv('data.csv', parse_dates=['Date'], index_col='Date') print(df.head()) Output:
 Loading the Dataset
Loading the Dataset3. Preprocessing the Data
We will scale our data to ensure all features have equal weight and avoid any bias. In this example, we will use MinMaxScaler, which scales the data to a range between 0 and 1. Proper scaling is important because neural networks tend to perform better when input features are normalized.
Python scaler = MinMaxScaler(feature_range=(0, 1)) scaled_data = scaler.fit_transform(df.values)
4. Preparing Data for GRU
We will define a function to prepare our data for training our model.
- create_dataset(): Prepares the dataset for time-series forecasting. It creates sliding windows of time_step length to predict the next time step.
- X.reshape(): Reshapes the input data to fit the expected shape for the GRU which is 3D: [samples, time steps, features].
Python def create_dataset(data, time_step=1): X, y = [], [] for i in range(len(data) - time_step - 1): X.append(data[i:(i + time_step), 0]) y.append(data[i + time_step, 0]) return np.array(X), np.array(y) time_step = 100 X, y = create_dataset(scaled_data, time_step) X = X.reshape(X.shape[0], X.shape[1], 1)
5. Building the GRU Model
We will define our GRU model with the following components:
- GRU(units=50): Adds a GRU layer with 50 units (neurons).
- return_sequences=True: Ensures that the GRU layer returns the entire sequence (required for stacking multiple GRU layers).
- Dense(units=1): The output layer which predicts a single value for the next time step.
- Adam(): An adaptive optimizer commonly used in deep learning.
Python model = Sequential() model.add(GRU(units=50, return_sequences=True, input_shape=(X.shape[1], 1))) model.add(GRU(units=50)) model.add(Dense(units=1)) model.compile(optimizer=Adam(learning_rate=0.001), loss='mean_squared_error')
Output:
 GRU Model
GRU Model6. Training the Model
model.fit() trains the model on the prepared dataset. The epochs=10 specifies the number of iterations over the entire dataset, and batch_size=32 defines the number of samples per batch.
Python model.fit(X, y, epochs=10, batch_size=32)
Output:
 Training the Model
Training the Model7. Making Predictions
We will be now making predictions using our trained GRU model.
- Input Sequence: The code takes the last 100 temperature values from the dataset (scaled_data[-time_step:]) as an input sequence.
- Reshaping the Input Sequence: The input sequence is reshaped into the shape (1, time_step, 1) because the GRU model expects a 3D input: [samples, time_steps, features]. Here samples=1 because we are making one prediction, time_steps=100 (the length of the input sequence) and features=1 because we are predicting only the temperature value.
- model.predict(): Uses the trained model to predict future values based on the input data.
Python input_sequence = scaled_data[-time_step:].reshape(1, time_step, 1) predicted_values = model.predict(input_sequence)
Output:
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 64ms/step
Inverse Transforming the Predictions refers to the process of converting the scaled (normalized) predictions back to their original scale.
- scaler.inverse_transform(): Converts the normalized predictions back to their original scale.
Python predicted_values = scaler.inverse_transform(predicted_values) print(f"The predicted temperature for the next day is: {predicted_values[0][0]:.2f}°C") Output:
The predicted temperature for the next day is: 25.03°C
The output 25.03^\omicron \text{C} is the GRU model's prediction for the next day's temperature based on the past 100 days of data. The model uses historical patterns to forecast future values and converts the prediction back to the original temperature scale.
Similar Reads
Deep Learning Tutorial Deep Learning tutorial covers the basics and more advanced topics, making it perfect for beginners and those with experience. Whether you're just starting or looking to expand your knowledge, this guide makes it easy to learn about the different technologies of Deep Learning.Deep Learning is a branc
5 min read
Introduction to Deep Learning
Basic Neural Network
Activation Functions
Artificial Neural Network
Classification
Regression
Hyperparameter tuning
Introduction to Convolution Neural Network
Introduction to Convolution Neural NetworkConvolutional Neural Network (CNN) is an advanced version of artificial neural networks (ANNs), primarily designed to extract features from grid-like matrix datasets. This is particularly useful for visual datasets such as images or videos, where data patterns play a crucial role. CNNs are widely us
8 min read
Digital Image Processing BasicsDigital Image Processing means processing digital image by means of a digital computer. We can also say that it is a use of computer algorithms, in order to get enhanced image either to extract some useful information. Digital image processing is the use of algorithms and mathematical models to proc
7 min read
Difference between Image Processing and Computer VisionImage processing and Computer Vision both are very exciting field of Computer Science. Computer Vision: In Computer Vision, computers or machines are made to gain high-level understanding from the input digital images or videos with the purpose of automating tasks that the human visual system can do
2 min read
CNN | Introduction to Pooling LayerPooling layer is used in CNNs to reduce the spatial dimensions (width and height) of the input feature maps while retaining the most important information. It involves sliding a two-dimensional filter over each channel of a feature map and summarizing the features within the region covered by the fi
5 min read
CIFAR-10 Image Classification in TensorFlowPrerequisites:Image ClassificationConvolution Neural Networks including basic pooling, convolution layers with normalization in neural networks, and dropout.Data Augmentation.Neural Networks.Numpy arrays.In this article, we are going to discuss how to classify images using TensorFlow. Image Classifi
8 min read
Implementation of a CNN based Image Classifier using PyTorchIntroduction: Introduced in the 1980s by Yann LeCun, Convolution Neural Networks(also called CNNs or ConvNets) have come a long way. From being employed for simple digit classification tasks, CNN-based architectures are being used very profoundly over much Deep Learning and Computer Vision-related t
9 min read
Convolutional Neural Network (CNN) ArchitecturesConvolutional Neural Network(CNN) is a neural network architecture in Deep Learning, used to recognize the pattern from structured arrays. However, over many years, CNN architectures have evolved. Many variants of the fundamental CNN Architecture This been developed, leading to amazing advances in t
11 min read
Object Detection vs Object Recognition vs Image SegmentationObject Recognition: Object recognition is the technique of identifying the object present in images and videos. It is one of the most important applications of machine learning and deep learning. The goal of this field is to teach machines to understand (recognize) the content of an image just like
5 min read
YOLO v2 - Object DetectionIn terms of speed, YOLO is one of the best models in object recognition, able to recognize objects and process frames at the rate up to 150 FPS for small networks. However, In terms of accuracy mAP, YOLO was not the state of the art model but has fairly good Mean average Precision (mAP) of 63% when
7 min read
Recurrent Neural Network
Natural Language Processing (NLP) TutorialNatural Language Processing (NLP) is the branch of Artificial Intelligence (AI) that gives the ability to machine understand and process human languages. Human languages can be in the form of text or audio format.Applications of NLPThe applications of Natural Language Processing are as follows:Voice
5 min read
NLTK - NLPNatural Language Toolkit (NLTK) is one of the largest Python libraries for performing various Natural Language Processing tasks. From rudimentary tasks such as text pre-processing to tasks like vectorized representation of text - NLTK's API has covered everything. In this article, we will accustom o
5 min read
Word Embeddings in NLPWord Embeddings are numeric representations of words in a lower-dimensional space, that capture semantic and syntactic information. They play a important role in Natural Language Processing (NLP) tasks. Here, we'll discuss some traditional and neural approaches used to implement Word Embeddings, suc
14 min read
Introduction to Recurrent Neural NetworksRecurrent Neural Networks (RNNs) differ from regular neural networks in how they process information. While standard neural networks pass information in one direction i.e from input to output, RNNs feed information back into the network at each step.Imagine reading a sentence and you try to predict
10 min read
Recurrent Neural Networks ExplanationToday, different Machine Learning techniques are used to handle different types of data. One of the most difficult types of data to handle and the forecast is sequential data. Sequential data is different from other types of data in the sense that while all the features of a typical dataset can be a
8 min read
Sentiment Analysis with an Recurrent Neural Networks (RNN)Recurrent Neural Networks (RNNs) are used in sequence tasks such as sentiment analysis due to their ability to capture context from sequential data. In this article we will be apply RNNs to analyze the sentiment of customer reviews from Swiggy food delivery platform. The goal is to classify reviews
5 min read
Short term MemoryIn the wider community of neurologists and those who are researching the brain, It is agreed that two temporarily distinct processes contribute to the acquisition and expression of brain functions. These variations can result in long-lasting alterations in neuron operations, for instance through act
5 min read
What is LSTM - Long Short Term Memory?Long Short-Term Memory (LSTM) is an enhanced version of the Recurrent Neural Network (RNN) designed by Hochreiter and Schmidhuber. LSTMs can capture long-term dependencies in sequential data making them ideal for tasks like language translation, speech recognition and time series forecasting. Unlike
5 min read
Long Short Term Memory Networks ExplanationPrerequisites: Recurrent Neural Networks To solve the problem of Vanishing and Exploding Gradients in a Deep Recurrent Neural Network, many variations were developed. One of the most famous of them is the Long Short Term Memory Network(LSTM). In concept, an LSTM recurrent unit tries to "remember" al
7 min read
LSTM - Derivation of Back propagation through timeLong Short-Term Memory (LSTM) are a type of neural network designed to handle long-term dependencies by handling the vanishing gradient problem. One of the fundamental techniques used to train LSTMs is Backpropagation Through Time (BPTT) where we have sequential data. In this article we see how BPTT
4 min read
Text Generation using Recurrent Long Short Term Memory NetworkLSTMs are a type of neural network that are well-suited for tasks involving sequential data such as text generation. They are particularly useful because they can remember long-term dependencies in the data which is crucial when dealing with text that often has context that spans over multiple words
4 min read