Classification of Text Documents using Naive Bayes
Last Updated : 16 May, 2025
In natural language processing and machine learning Naive Bayes is a popular method for classifying text documents. It can be used to classifies documents into pre defined types based on likelihood of a word occurring by using Bayes theorem. In this article we will implement Text Classification using Naive Bayes in Python.
 Text Classification using Naive Bayes
Text Classification using Naive BayesThe dataset we will be using will be of text data categorized into four labels: Technology, Sports, Politics and Entertainment. Each entry contains a short sentence or statement related to a specific topic with the label indicating the category it belongs to.
1. Importing Libraries
We will need to import the necessary libraries like scikit-learn, Pandas and Numpy.
- CountVectorizer to convert text data into numerical features using word counts.
- MultinomialNB: The Naive Bayes classifier for multinomial data and is ideal for text classification.
Python import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import CountVectorizer from sklearn.naive_bayes import MultinomialNB from sklearn.metrics import accuracy_score, confusion_matrix from sklearn.feature_extraction.text import CountVectorizer
2. Loading the Dataset
You can download the dataset from here.
Python data = pd.read_csv('synthetic_text_data.csv') X = data['text'] y = data['label'] 3. Splitting the Data
Now we split the dataset into training and testing sets. The training set is used to train the model while the testing set is used to evaluate its performance.
- train_test_split: Splits the data into training (80%) and testing (20%) sets.
- random_state: ensures reproducibility.
Python X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
4. Text Preprocessing: Converting Text to Numeric Features
We need to convert the text data into numerical format before feeding it to the model. We use CountVectorizer to convert the text into a matrix of token counts.
- CountVectorizer(): Converts the raw text into a matrix of word counts.
- fit_transform(): Learns the vocabulary from the training data and transforms the text into vector.
- transform(): Applies the learned vocabulary from the training data to the test data.
Python vectorizer = CountVectorizer() X_train_vectorized = vectorizer.fit_transform(X_train) X_test_vectorized = vectorizer.transform(X_test)
5. Training the Naive Bayes Classifier
With the data now in the right format we train the Naive Bayes classifier on the training data. Here we use Multinomial Naive Bayes.
Multinomial Naive Bayes is a variant of the Naive Bayes classifier specifically suited for classification tasks where the features or input data are discrete such as word counts or frequencies in text classification.
Python model = MultinomialNB() model.fit(X_train_vectorized, y_train)
6. Making Predictions
Now that the model is trained we can use it to predict the labels for the test data using X_test_vectorized.
Python y_pred = model.predict(X_test_vectorized)
7. Evaluating the Model
After making predictions we need to evaluate the model's performance. We'll calculate the accuracy and confusion matrix to understand how well the model is performing.
- accuracy_score(): Calculates the accuracy of the model by comparing the predicted labels (y_pred) with the true labels (y_test).
- confusion_matrix(): Generates a confusion matrix to visualize how well the model classifies each category.
Python accuracy = accuracy_score(y_test, y_pred) conf_matrix = confusion_matrix(y_test, y_pred) print(f'Accuracy: {accuracy *100}%') class_labels = np.unique(y_test) plt.figure(figsize=(8, 6)) sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', xticklabels=class_labels, yticklabels=class_labels) plt.title('Confusion Matrix Heatmap') plt.xlabel('Predicted Label') plt.ylabel('True Label') plt.show() Output:
Accuracy: 88.23529411764706%
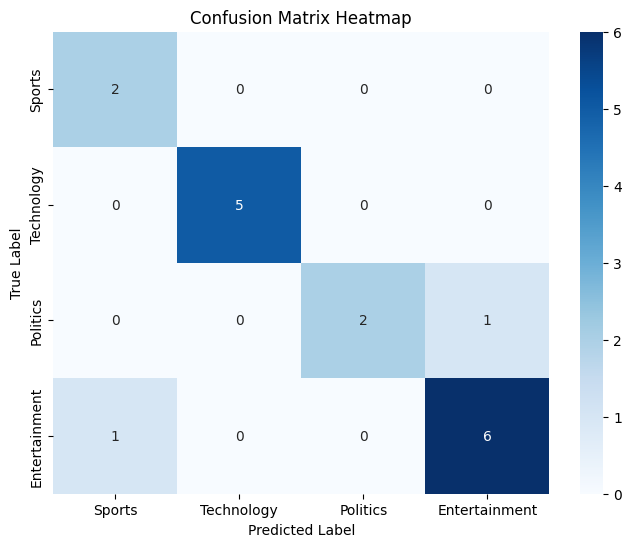 Confusion Matrix
Confusion MatrixThe accuracy of the model is approximately 88% meaning it correctly predicted the categories for about 88% of the test data.
Looking at the confusion matrix heatmap we can see the model made correct predictions for Sports (2), Technology (5), Politics (2) and Entertainment (6). Heatmap shows these values with darker colors representing correct predictions. However there were some misclassifications.
8. Prediction on Unseen Data
Python user_input = ("I love artificial intelligence and machine learning") user_input_vectorized = vectorizer.transform([user_input]) predicted_label = model.predict(user_input_vectorized) print(f"The input text belongs to the '{predicted_label[0]}' category.") Output:
The input text belongs to the 'Technology' category.
Here we can see our model is working fine and can predict on unseen data accurately. Naive Bayes is a strong baseline model for text classification tasks especially when the dataset is large and the features (words) are relatively independent.
Similar Reads
Naive Bayes vs. SVM for Text Classification Text classification is a fundamental task in natural language processing (NLP), with applications ranging from spam detection to sentiment analysis and document categorization. Two popular machine learning algorithms for text classification are Naive Bayes classifier (NB) and Support Vector Machines
9 min read
Text classification using CNN Text classification is a widely used NLP task in different business problems, and using Convolution Neural Networks (CNNs) has become the most popular choice. In this article, you will learn about the basics of Convolutional neural networks and the implementation of text classification using CNNs, a
5 min read
Toxic Comment Classification using BERT Social media users frequently encounter abuse, harassment, and insults from other users on a majority of online communication platforms like Facebook, Instagram and Youtube due to which many users stop expressing their ideas and opinions. What is the solution? The solution to this problem is to crea
15+ min read
Text Classification using Logistic Regression Text classification is a fundamental task in Natural Language Processing (NLP) that involves assigning predefined categories or labels to textual data. It has a wide range of applications, including spam detection, sentiment analysis, topic categorization, and language identification. Logistic Regre
4 min read
Text Classification using Decision Trees in Python Text classification is the process of classifying the text documents into predefined categories. In this article, we are going to explore how we can leverage decision trees to classify the textual data. Text Classification and Decision Trees Text classification involves assigning predefined categori
5 min read