Google is known for its challenging technical interviews and SQL is a key component of these interviews, especially for roles related to data analysis, database engineering, and backend development.
Google SQL interview questions typically focus on candidates' proficiency in writing complex SQL queries, optimizing database operations, and demonstrating a deep understanding of relational database concepts.
In this article, we'll cover some common SQL interview questions you might encounter in a Google interview, detailed explanations, and sample queries.

Top 15 Google SQL Interview Questions
1. Find the Employees with More Than One Manager
Let's Retrieve the employee_id and employee_name of employees who have more than one manager from the employee_managers table.
Table: employee_managers
| employee_id | employee_name | manager_id | manager_name |
|---|
| 1 | Alice | 101 | Bob |
| 1 | Alice | 102 | Charlie |
| 2 | David | 101 | Bob |
| 3 | Eve | 103 | Frank |
| 4 | Grace | 104 | Henry |
| 4 | Grace | 105 | Ivy |
| 5 | Jack | 106 | Ken |
Query:
SELECT employee_id, employee_name
FROM employee_managers
GROUP BY employee_id, employee_name
HAVING COUNT(DISTINCT manager_id) > 1;
Output:

Explanation: This query groups the table by employee_id and employee_name, then filters the groups to include only those where the count of distinct manager_id is greater than one, indicating employees with more than one manager.
2. Write a SQL Query to Find Employees Who Have Worked in All Departments
Given a `works_in` table Find employees who have worked in all departments.
Table: works_in
employee_id | department_id |
|---|
| 1 | 1 |
| 1 | 2 |
| 1 | 3 |
| 2 | 1 |
| 2 | 2 |
| 3 | 1 |
| 3 | 3 |
| 4 | 2 |
| 4 | 3 |
| 4 | 4 |
| 5 | 1 |
| 5 | 2 |
| 5 | 3 |
| 5 | 4 |
Query:
SELECT employee_id
FROM works_in
GROUP BY employee_id
HAVING COUNT(DISTINCT department_id)
=
(SELECT COUNT(*) FROM (SELECT DISTINCT department_id FROM works_in) AS departments);
Output:
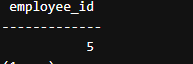
Explanation:This query groups employees by employee_id, counts the distinct department_id values for each employee, and filters to include only those employees whose count matches the total number of distinct departments in the company
3. What is Database Denormalization?
- Performance Optimization: Denormalization is used to improve the performance of read operations by reducing the number of joins needed to retrieve data.
- Redundant Data: It involves adding redundant copies of data or grouping data together to simplify queries and reduce the need for joins.
- Read-Heavy Workloads: Denormalization is most beneficial for databases with read-heavy workloads where the performance gain from simplified queries the cost of increased storage and potential data inconsistency.
- Data Maintenance: It can increase the complexity of data maintenance and the risk of inconsistencies, as redundant data needs to be kept in sync with the original data.
- Careful Consideration: Denormalization should be carefully considered and implemented based on specific performance needs, as over-denormalization can lead to excessive redundancy and complexity.
- Balancing Act: It is a balancing act between improving read performance and maintaining data integrity and consistency.
4. SQL Query to Rank Employees from Different Departments
Given a `employees` table and we have to write a query to Rank employees within each department based on their salaries and rank departments based on their IDs.
Table: employees
employee_id | department_id | salary |
|---|
| 1 | 1 | 60000 |
| 2 | 1 | 65000 |
| 3 | 2 | 70000 |
| 4 | 2 | 72000 |
| 5 | 3 | 80000 |
| 6 | 3 | 85000 |
Query:
WITH RankedEmployees AS (
SELECT
employee_id,
department_id,
salary,
DENSE_RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS dept_salary_rank,
DENSE_RANK() OVER (ORDER BY department_id) AS dept_name_rank
FROM employees
)
SELECT
employee_id,
department_id,
salary,
dept_salary_rank,
dept_name_rank
FROM RankedEmployees
ORDER BY dept_name_rank, dept_salary_rank;
Output:

Explanation:This query uses window functions to assign ranks to employees within each department based on their salaries (dept_salary_rank) and to departments based on their IDs (dept_name_rank). The results are ordered initially by the rank of department names and then by the rank of department salaries.
5. SQL Query to Find the Median Salary in the Company
Given a employee table and we have to Find the median salary in the company. The median should be determined by finding the middle values of the ordered list of search counts
Table: employee
id | name | company | salary |
|---|
| 1 | Alice | Google | 90000 |
| 2 | Bob | Google | 95000 |
| 3 | Charlie | Google | 100000 |
| 4 | David | Google | 105000 |
| 5 | Eve | Google | 110000 |
| 6 | Frank | Google | 115000 |
Query:
WITH RankedSalaries AS (
SELECT salary, ROW_NUMBER() OVER (ORDER BY salary) AS row_num,
COUNT(*) OVER () AS total_rows
FROM employee
)
SELECT AVG(salary) AS median_salary
FROM RankedSalaries
WHERE row_num IN ((total_rows + 1) / 2, (total_rows + 2) / 2);
Output:

Explanation:This query calculates the median salary by ranking the salaries in ascending order, determining the total number of rows, and then averaging the salaries corresponding to the middle row or rows if the total count is even.
6. Understanding the EXCEPT Operator in SQL Server and the MINUS Operator in Oracle
The EXCEPT operator in SQL Server and MINUS in Oracle is used to return all distinct rows from the first query that are not also returned by the second query. It essentially performs a set difference operation, removing the results of one query from another.
| Feature | EXCEPT (SQL Server) | MINUS (Oracle) |
|---|
| Syntax | SELECT ... FROM table1 EXCEPT SELECT ... FROM table2; | SELECT ... FROM table1 MINUS SELECT ... FROM table2; |
| Returns | Rows from the first query that are not in the second | Rows from the first query that are not in the second |
| Columns | Number and order of columns must match in both queries | Number and order of columns must match in both queries |
| Data Types | Data types must be compatible | Data types must be compatible |
7. SQL Query to Analyzing User Clicks
Given a table called user_clicks write a query to Find users who have clicked on more than one page.
Table: user_clicks
user_id | timestamp | page_id | action_type |
|---|
| 1 | 2024-06-18 08:30:00 | 101 | "click" |
| 2 | 2024-06-18 08:31:00 | 102 | "click" |
| 1 | 2024-06-18 08:32:00 | 103 | "click" |
| 3 | 2024-06-18 08:33:00 | 101 | "click" |
| 1 | 2024-06-18 08:34:00 | 101 | "click" |
Query:
SELECT user_id
FROM user_clicks
GROUP BY user_id
HAVING COUNT(DISTINCT page_id) > 1;
Output:

Explanation: This query selects user_id from user_clicks, groups the results by user_id, and filters the groups to include only those with more than one distinct page_id, indicating users who have clicked on multiple pages.
8. How to Structure the Tables to Efficiently Store and Query the Survey Responses?
To efficiently store and query survey responses in SQL, you can structure the tables as follows:
1. Survey Table: Contains information about each survey, such as the survey ID, title, description, and any other relevant metadata.
CREATE TABLE Survey (
survey_id INT PRIMARY KEY,
title VARCHAR(255),
description TEXT
);
2. Question Table: Contains information about each question in the survey, including the question ID, text, type (e.g., multiple choice, text), and the survey it belongs to.
CREATE TABLE Question (
question_id INT PRIMARY KEY,
survey_id INT,
text TEXT,
type VARCHAR(50),
FOREIGN KEY (survey_id) REFERENCES Survey(survey_id)
);
3.Response Table: Stores the responses to each question in the survey, with each response linked to a specific respondent and question.
CREATE TABLE Response (
response_id INT PRIMARY KEY,
question_id INT,
respondent_id INT,
response_text TEXT,
FOREIGN KEY (question_id) REFERENCES Question(question_id),
FOREIGN KEY (respondent_id) REFERENCES Respondent(respondent_id)
);
4.Respondent Table: Contains information about each respondent, such as their ID, demographics, and any other relevant information.
CREATE TABLE Respondent (
respondent_id INT PRIMARY KEY,
age INT,
gender VARCHAR(50),
location VARCHAR(255),
-- Other demographic information
);
This structure allows you to efficiently store and query survey responses. You can easily retrieve responses for a specific survey, question, or respondent, and perform analysis or reporting as needed.
9. Write a Query to Find the Number of Pages That are Currently Active and have the Latest Event
Given a table pages with columns page_id, status, and event_date, write a SQL query to count the number of active pages that have the latest event date among all events for each page. An active page is defined as a page with status = 'active'. Consider each row in the pages table as a single event for a page.
Table: pages
| page_id | page_name | status | event_date |
|---|
| 1 | Home | active | 2022-06-01 |
| 2 | About Us | active | 2022-05-30 |
| 3 | Contact Us | active | 2022-06-02 |
| 4 | Products | active | 2022-05-29 |
| 5 | Services | active | 2022-06-03 |
Query:
SELECT COUNT(*) AS active_pages_with_latest_event
FROM pages p1
WHERE status = 'active'
AND NOT EXISTS (
SELECT 1
FROM pages p2
WHERE p2.page_id = p1.page_id
AND p2.event_date > p1.event_date
);
Output:

Explanation:This query counts the number of active pages (`status = 'active'`) that have the latest event date (`event_date`) among all events for each page. It uses a correlated subquery with `NOT EXISTS` to check if there are no other events for the same page (`p2.page_id = p1.page_id`) with a later `event_date`. If there are no such events, the page is considered to have the latest event date.
10. SQL Query to Find Users with High Click Volume
Given a user_clicks table containing users data, the task is to Find users who have clicked more than 3 times.
Table: user_clicks
user_id | timestamp | page_id | action_type |
|---|
| 1 | 2024-06-18 08:30:00 | 101 | "click" |
| 2 | 2024-06-18 08:31:00 | 102 | "click" |
| 1 | 2024-06-18 08:32:00 | 103 | "click" |
| 3 | 2024-06-18 08:33:00 | 101 | "click" |
| 1 | 2024-06-18 08:34:00 | 101 | "click" |
| 1 | 2024-06-18 08:35:00 | 102 | "click" |
| 2 | 2024-06-18 08:36:00 | 103 | "click" |
| 3 | 2024-06-18 08:37:00 | 104 | "click" |
| 3 | 2024-06-18 08:38:00 | 105 | "click" |
| 3 | 2024-06-18 08:39:00 | 106 | "click" |
| 1 | 2024-06-18 08:40:00 | 107 | "click" |
| 2 | 2024-06-18 08:41:00 | 108 | "click" |
| 1 | 2024-06-18 08:42:00 | 109 | "click" |
Query:
SELECT user_id, COUNT(*) AS click_count
FROM user_clicks
GROUP BY user_id
HAVING click_count > 3;
Output:

Explanation: This query calculates the click count for each user (user_id) in the user_clicks table, grouping the results by user_id. The HAVING clause filters the groups to include only those with a click count (click_count) greater than 3.
11. Determine Overlapping Subscription Date Ranges for Users in a Product Subscriptions Table
Write a query to check if there is any overlap in subscription date ranges among users in the `ProductSubscriptions` table. Return a list of users along with a boolean value indicating if there is an overlap.
Table: ProductSubscriptions
| UserId | HasOverlappingSubscription |
|---|
| 1 | True |
| 2 | True |
| 3 | True |
| 4 | True |
| 5 | True |
Query:
SELECT ps1.UserId,
CASE
WHEN EXISTS (
SELECT 1
FROM ProductSubscriptions ps2
WHERE ps2.UserId <> ps1.UserId
AND ps2.StartDate <= ps1.EndDate
AND ps2.EndDate >= ps1.StartDate
) THEN 'True'
ELSE 'False'
END AS HasOverlappingSubscription
FROM ProductSubscriptions ps1;
Output:

Explanation:This query checks for overlapping subscription date ranges for each user in the ProductSubscriptions table. It uses a self-join to compare each user's subscription dates (ps1) with those of all other users (ps2). If any overlap is found, it returns 'True'; otherwise, it returns 'False' for each user.
12. Calculate Cumulative Daily New Users with Monthly Reset
Here's an example of what the users table might look like:
| UserId | SignUpDate |
|---|
| 1 | 2024-01-01 |
| 2 | 2024-01-02 |
| 3 | 2024-01-05 |
| 4 | 2024-02-01 |
| 5 | 2024-02-05 |
| 6 | 2024-02-10 |
| 7 | 2024-03-01 |
| 8 | 2024-03-02 |
| 9 | 2024-03-03 |
Query:
SELECT
SignUpDate,
COUNT(UserId) OVER (PARTITION BY EXTRACT(YEAR FROM SignUpDate), EXTRACT(MONTH FROM SignUpDate) ORDER BY SignUpDate) AS CumulativeUserCount
FROM
users
ORDER BY
SignUpDate;
Output:
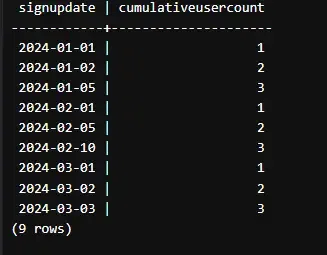
Explanation:This query calculates the cumulative number of new users added each day, with the count resetting at the beginning of every month. It uses the `COUNT()` window function with `PARTITION BY EXTRACT(YEAR FROM SignUpDate), EXTRACT(MONTH FROM SignUpDate)` to group the data by year and month, and `ORDER BY SignUpDate` to order the rows within each group by the sign-up date. This allows the count to reset for each month, providing a cumulative count of new users.
13. Analyzing Google Ad Campaign Performance with a SQL Query
Given a table google_ad_performance containing data about various Google ad campaigns, write a SQL query to calculate the total clicks, conversions, total cost, total revenue, and profit (revenue - cost) for each campaign. Group the results by campaign_id.
Table: google_ad_performance
| date | campaign_id | clicks | conversions | cost | revenue |
|---|
| 2024-01-01 | 1 | 100 | 5 | 50.00 | 100.00 |
| 2024-01-01 | 2 | 120 | 6 | 60.00 | 110.00 |
| 2024-01-02 | 1 | 110 | 4 | 45.00 | 95.00 |
| 2024-01-02 | 2 | 130 | 7 | 65.00 | 120.00 |
Query:
SELECT
campaign_id,
SUM(clicks) AS total_clicks,
SUM(conversions) AS total_conversions,
SUM(cost) AS total_cost,
SUM(revenue) AS total_revenue,
SUM(revenue) - SUM(cost) AS profit
FROM
google_ad_performance
GROUP BY
campaign_id;
Output:

14. Filtering Odd and Even Measurements Using a SQL Query
Given a table `measurements` with a column `value`, write a query to categorize each value in the `value` column as either 'Even' or 'Odd', and return the original value along with its category.
Table: measurements
| id | value |
|---|
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 4 |
| 5 | 5 |
| 6 | 6 |
| 7 | 7 |
| 8 | 8 |
| 9 | 9 |
| 10 | 10 |
Query:
SELECT
value,
CASE
WHEN value % 2 = 0 THEN 'Even'
ELSE 'Odd'
END AS category
FROM
measurements;
Output:

Explanation:This query selects the `value` column from the `measurements` table and uses a `CASE` statement to categorize each value as either 'Even' or 'Odd'. If the value is divisible by 2 (`value % 2 = 0`), it is categorized as 'Even', otherwise it is categorized as 'Odd'. The result set includes the original `value` column and a new `category` column indicating whether each value is odd or even.
15. SQL Query to Find Locations within a Radius in Google Mapped Table
Let's Find locations within a 50 km radius of a specific latitude and longitude coordinate from the Google_mapped table.
Table: Google_mapped
id | location_name | latitude | longitude |
|---|
| 1 | Location A | 37.774929 | -122.419416 |
| 2 | Location B | 34.052235 | -118.243683 |
| 3 | Location C | 40.712776 | -74.005974 |
| 4 | Location D | 51.507351 | -0.127758 |
| 5 | Location E | 48.856613 | 2.352222 |
Query:
SELECT
id,
location_name,
latitude,
longitude
FROM
Google_mapped
WHERE
6371 * 2 * ASIN(SQRT(
POWER(SIN((37.774929 - ABS(latitude)) * PI() / 180 / 2), 2) +
COS(37.774929 * PI() / 180) * COS(ABS(latitude) * PI() / 180) *
POWER(SIN((-122.419416 - longitude) * PI() / 180 / 2), 2)
)) <= 50;
Output:
| id | location_name | latitude | longitude |
|---|
| 1 | Location A | 37.774929 | -122.419416 |
Explanation:This query retrieves the `id`, `location_name`, `latitude`, and `longitude` columns from the `Google_mapped` table. It filters the results to include only locations that are within a 50 km radius of the coordinates (37.774929, -122.419416) using the Haversine formula to calculate distances on a spherical Earth model. The `ASIN(SQRT(...))` part calculates the distance between each location and the specified coordinates, and the `WHERE` clause filters the results to include only locations within the specified radius.
Tips & Tricks to Clear SQL Interview Questions
- Understand the Basics: Ensure you have a solid understanding of fundamental SQL concepts like SELECT statements, WHERE clauses, joins, and aggregate functions.
- Practice Regularly: Regular practice with a variety of SQL problems is key. Use online platforms or SQL databases to practice writing and optimizing queries.
- Learn Advanced Concepts: Beyond the basics, familiarize yourself with advanced SQL topics like window functions, CTEs (Common Table Expressions), and subqueries.
- Optimize Your Queries: Learn how to write efficient queries and understand the importance of indexing and query optimization techniques.
- Real-World Scenarios: Try to work on real-world datasets and problems. This will help you understand the practical applications of SQL and prepare you for scenario-based questions.
- Review and Refactor: Regularly review your queries and seek feedback. Refactor your queries for better performance and readability.
Conclusion
In this article, we covered various SQL queries and concepts relevant to Google SQL interviews. Topics included identifying top Google search users, analyzing ad campaign performance, and handling flagged user-generated content. These examples provide a comprehensive overview of common SQL scenarios encountered in Google-related roles.
Similar Reads
Google Bangalore Interview Experience Initial HR Discussion: Some recruiter from Singapore contacts through my google mail. She asked basic questions related to sorting algorithms.  Which is better heap sort or merge sort ? Why ?.  In which data structures log n time search is guaranteed [Binary tree, Hash Map,  BST, Arrays] What is t
1 min read
Top 50 Most Asked Google Tricky Interview Questions Google is a dream workplace for every software developer to work in, It is one of the best in every aspect, be it the projects their employees work on or work-life balance. So, to be a part of such an awesome workplace one must be adequately prepared for its Technical and behavioral rounds of the hi
15+ min read
Google Interview Experience | Set 4 Though I didn't clear google but I want to share my Google interview experience , so it can help other's . Please find my interview experience below: My Google Interview Experience for Software Developer Position [Android Core Team], London, United Kingdom Like many other enthusiastic engineers, I t
3 min read
Google Interview Questions As per, the Google Career Page there are two types of interviews, Phone/Hangout interviews, and Onsite Interviews. Below is an excerpt for their official page. For software engineering candidates, we want to understand your coding skills and technical areas of expertise, including tools or programmi
3 min read
Google SDE Sheet: Interview Questions and Answers Google is an American multinational technology company specializing in search engine technology, online advertising, cloud computing, computer software, quantum computing, e-commerce, and artificial intelligence. It is a dream of many people to work for Google. This sheet will assist you to land a j
8 min read