Computer Organization | Different Instruction Cycles
Last Updated : 19 Apr, 2023
Introduction :
Prerequisite - Execution, Stages and Throughput
Registers Involved In Each Instruction Cycle:
- Memory address registers(MAR) : It is connected to the address lines of the system bus. It specifies the address in memory for a read or write operation.
- Memory Buffer Register(MBR) : It is connected to the data lines of the system bus. It contains the value to be stored in memory or the last value read from the memory.
- Program Counter(PC) : Holds the address of the next instruction to be fetched.
- Instruction Register(IR) : Holds the last instruction fetched.
In computer organization, an instruction cycle, also known as a fetch-decode-execute cycle, is the basic operation performed by a central processing unit (CPU) to execute an instruction. The instruction cycle consists of several steps, each of which performs a specific function in the execution of the instruction. The major steps in the instruction cycle are:
- Fetch: In the fetch cycle, the CPU retrieves the instruction from memory. The instruction is typically stored at the address specified by the program counter (PC). The PC is then incremented to point to the next instruction in memory.
- Decode: In the decode cycle, the CPU interprets the instruction and determines what operation needs to be performed. This involves identifying the opcode and any operands that are needed to execute the instruction.
- Execute: In the execute cycle, the CPU performs the operation specified by the instruction. This may involve reading or writing data from or to memory, performing arithmetic or logic operations on data, or manipulating the control flow of the program.
- There are also some additional steps that may be performed during the instruction cycle, depending on the CPU architecture and instruction set:
- Fetch operands: In some CPUs, the operands needed for an instruction are fetched during a separate cycle before the execute cycle. This is called the fetch operands cycle.
- Store results: In some CPUs, the results of an instruction are stored during a separate cycle after the execute cycle. This is called the store results cycle.
- Interrupt handling: In some CPUs, interrupt handling may occur during any cycle of the instruction cycle. An interrupt is a signal that the CPU receives from an external device or software that requires immediate attention. When an interrupt occurs, the CPU suspends the current instruction and executes an interrupt handler to service the interrupt.
These cycles are the basic building blocks of the CPU's operation and are performed for every instruction executed by the CPU. By optimizing these cycles, CPU designers can improve the performance and efficiency of the CPU, allowing it to execute instructions faster and more efficiently.
The Instruction Cycle -
Each phase of Instruction Cycle can be decomposed into a sequence of elementary micro-operations. In the above examples, there is one sequence each for the Fetch, Indirect, Execute and Interrupt Cycles.

The Indirect Cycle is always followed by the Execute Cycle. The Interrupt Cycle is always followed by the Fetch Cycle. For both fetch and execute cycles, the next cycle depends on the state of the system.

We assumed a new 2-bit register called Instruction Cycle Code (ICC). The ICC designates the state of processor in terms of which portion of the cycle it is in:-
00 : Fetch Cycle
01 : Indirect Cycle
10 : Execute Cycle
11 : Interrupt Cycle
At the end of the each cycles, the ICC is set appropriately. The above flowchart of Instruction Cycle describes the complete sequence of micro-operations, depending only on the instruction sequence and the interrupt pattern(this is a simplified example). The operation of the processor is described as the performance of a sequence of micro-operation.
Different Instruction Cycles:
- The Fetch Cycle -
At the beginning of the fetch cycle, the address of the next instruction to be executed is in the Program Counter(PC).

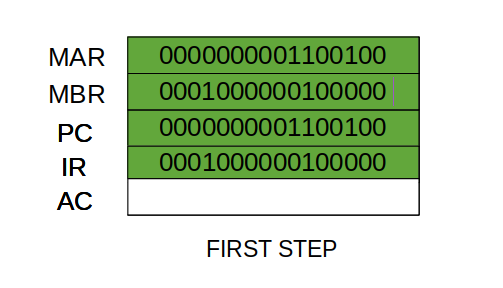
- Step 1: The address in the program counter is moved to the memory address register(MAR), as this is the only register which is connected to address lines of the system bus.

- Step 2: The address in MAR is placed on the address bus, now the control unit issues a READ command on the control bus, and the result appears on the data bus and is then copied into the memory buffer register(MBR). Program counter is incremented by one, to get ready for the next instruction. (These two action can be performed simultaneously to save time)
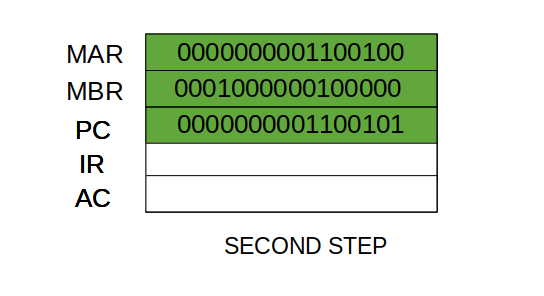
- Step 3: The content of the MBR is moved to the instruction register(IR).
- Thus, a simple Fetch Cycle consist of three steps and four micro-operation. Symbolically, we can write these sequence of events as follows:-

- Here 'I' is the instruction length. The notations (t1, t2, t3) represents successive time units. We assume that a clock is available for timing purposes and it emits regularly spaced clock pulses. Each clock pulse defines a time unit. Thus, all time units are of equal duration. Each micro-operation can be performed within the time of a single time unit.
First time unit: Move the contents of the PC to MAR.
Second time unit: Move contents of memory location specified by MAR to MBR. Increment content of PC by I.
Third time unit: Move contents of MBR to IR.
Note: Second and third micro-operations both take place during the second time unit.
- The Indirect Cycles -
Once an instruction is fetched, the next step is to fetch source operands. Source Operand is being fetched by indirect addressing( it can be fetched by any addressing mode, here its done by indirect addressing). Register-based operands need not be fetched. Once the opcode is executed, a similar process may be needed to store the result in main memory. Following micro-operations takes place:-

- Step 1: The address field of the instruction is transferred to the MAR. This is used to fetch the address of the operand.
Step 2: The address field of the IR is updated from the MBR.(So that it now contains a direct addressing rather than indirect addressing)
Step 3: The IR is now in the state, as if indirect addressing has not been occurred.
Note: Now IR is ready for the execute cycle, but it skips that cycle for a moment to consider the Interrupt Cycle .
- The Execute Cycle
The other three cycles(Fetch, Indirect and Interrupt) are simple and predictable. Each of them requires simple, small and fixed sequence of micro-operation. In each case same micro-operation are repeated each time around.
Execute Cycle is different from them. Like, for a machine with N different opcodes there are N different sequence of micro-operations that can occur.
Lets take an hypothetical example :-
consider an add instruction:

- Here, this instruction adds the content of location X to register R. Corresponding micro-operation will be:-

- We begin with the IR containing the ADD instruction.
Step 1: The address portion of IR is loaded into the MAR.
Step 2: The address field of the IR is updated from the MBR, so the reference memory location is read.
Step 3: Now, the contents of R and MBR are added by the ALU.
Lets take a complex example :-

- Here, the content of location X is incremented by 1. If the result is 0, the next instruction will be skipped. Corresponding sequence of micro-operation will be :-

- Here, the PC is incremented if (MBR) = 0. This test (is MBR equal to zero or not) and action (PC is incremented by 1) can be implemented as one micro-operation.
Note : This test and action micro-operation can be performed during the same time unit during which the updated value MBR is stored back to memory.
- The Interrupt Cycle:
At the completion of the Execute Cycle, a test is made to determine whether any enabled interrupt has occurred or not. If an enabled interrupt has occurred then Interrupt Cycle occurs. The nature of this cycle varies greatly from one machine to another.
Lets take a sequence of micro-operation:-

- Step 1: Contents of the PC is transferred to the MBR, so that they can be saved for return.
Step 2: MAR is loaded with the address at which the contents of the PC are to be saved.
PC is loaded with the address of the start of the interrupt-processing routine.
Step 3: MBR, containing the old value of PC, is stored in memory.
Note: In step 2, two actions are implemented as one micro-operation. However, most processor provide multiple types of interrupts, it may take one or more micro-operation to obtain the save_address and the routine_address before they are transferred to the MAR and PC respectively.
Uses of Different Instruction Cycles :
Here are some uses of different instruction cycles:
- Fetch cycle: This cycle retrieves the instruction from memory and loads it into the processor's instruction register. The fetch cycle is essential for the processor to know what instruction it needs to execute.
- Decode cycle: This cycle decodes the instruction to determine what operation it represents and what operands it requires. The decode cycle is important for the processor to understand what it needs to do with the instruction and what data it needs to retrieve or manipulate.
- Execute cycle: This cycle performs the actual operation specified by the instruction, using the operands specified in the instruction or in other registers. The execute cycle is where the processor performs the actual computation or manipulation of data.
- Store cycle: This cycle stores the result of the operation in memory or in a register. The store cycle is essential for the processor to save the result of the computation or manipulation for future use.
The advantages and disadvantages of the instruction cycle depend on various factors, such as the specific CPU architecture and the instruction set used. However, here are some general advantages and disadvantages of the instruction cycle:
Advantages:
- Standardization: The instruction cycle provides a standard way for CPUs to execute instructions, which allows software developers to write programs that can run on multiple CPU architectures. This standardization also makes it easier for hardware designers to build CPUs that can execute a wide range of instructions.
- Efficiency: By breaking down the instruction execution into multiple steps, the CPU can execute instructions more efficiently. For example, while the CPU is performing the execute cycle for one instruction, it can simultaneously fetch the next instruction.
- Pipelining: The instruction cycle can be pipelined, which means that multiple instructions can be in different stages of execution at the same time. This improves the overall performance of the CPU, as it can process multiple instructions simultaneously.
Disadvantages:
- Overhead: The instruction cycle adds overhead to the execution of instructions, as each instruction must go through multiple stages before it can be executed. This overhead can reduce the overall performance of the CPU.
- Complexity: The instruction cycle can be complex to implement, especially if the CPU architecture and instruction set are complex. This complexity can make it difficult to design, implement, and debug the CPU.
- Limited parallelism: While pipelining can improve the performance of the CPU, it also has limitations. For example, some instructions may depend on the results of previous instructions, which limits the amount of parallelism that can be achieved. This can reduce the effectiveness of pipelining and limit the overall performance of the CPU.
Issues of Different Instruction Cycles :
Here are some common issues associated with different instruction cycles:
- Pipeline hazards: Pipelining is a technique used to overlap the execution of multiple instructions by breaking them into smaller stages. However, pipeline hazards occur when one instruction depends on the completion of a previous instruction, leading to delays and reduced performance.
- Branch prediction errors: Branch prediction is a technique used to anticipate which direction a program will take when encountering a conditional branch instruction. However, if the prediction is incorrect, it can result in wasted cycles and decreased performance.
- Instruction cache misses: Instruction cache is a fast memory used to store frequently used instructions. Instruction cache misses occur when an instruction is not found in the cache and needs to be retrieved from slower memory, resulting in delays and decreased performance.
- Instruction-level parallelism limitations: Instruction-level parallelism is the ability of a processor to execute multiple instructions simultaneously. However, this technique has limitations as not all instructions can be executed in parallel, leading to reduced performance in some cases.
- Resource contention: Resource contention occurs when multiple instructions require the use of the same resource, such as a register or a memory location. This can lead to delays and reduced performance if the processor is unable to resolve the contention efficiently.
Similar Reads
Machine instructions and addressing modes
Computer Organization - Von Neumann architectureComputer Organization is like understanding the "blueprint" of how a computer works internally. One of the most important models in this field is the Von Neumann architecture, which is the foundation of most modern computers. Named after John von Neumann, this architecture introduced the concept of
6 min read
Computer Organization - Basic Computer InstructionsComputer organization refers to the way in which the components of a computer system are organized and interconnected to perform specific tasks. One of the most fundamental aspects of computer organization is the set of basic computer instructions that the system can execute.Basic Computer Instructi
6 min read
Computer Organization | Instruction Formats (Zero, One, Two and Three Address Instruction)Instruction formats refer to the way instructions are encoded and represented in machine language. There are several types of instruction formats, including zero, one, two, and three-address instructions. Each type of instruction format has its own advantages and disadvantages in terms of code size,
11 min read
Stack based CPU OrganizationBased on the number of address fields, CPU organization is of three types: Single Accumulator organization, register based organization and stack based CPU organization.Stack-Based CPU OrganizationThe computers which use Stack-based CPU Organization are based on a data structure called a stack. The
4 min read
Introduction of General Register based CPU OrganizationWhen we are using multiple general-purpose registers, instead of a single accumulator register, in the CPU Organization then this type of organization is known as General register-based CPU Organization. In this type of organization, the computer uses two or three address fields in their instruction
3 min read
Introduction of Single Accumulator based CPU organizationThe computers, present in the early days of computer history, had accumulator-based CPUs. In this type of CPU organization, the accumulator register is used implicitly for processing all instructions of a program and storing the results into the accumulator. The instruction format that is used by th
2 min read
Computer Organization | Problem Solving on Instruction FormatPrerequisite - Basic Computer Instructions, Instruction Formats Problem statement: Consider a computer architecture where instructions are 16 bits long. The first 6 bits of the instruction are reserved for the opcode, and the remaining 10 bits are used for the operands. There are three addressing mo
7 min read
Addressing ModesAddressing modes are the techniques used by the CPU to identify where the data needed for an operation is stored. They provide rules for interpreting or modifying the address field in an instruction before accessing the operand.Addressing modes for 8086 instructions are divided into two categories:
7 min read
Machine InstructionsMachine Instructions are commands or programs written in the machine code of a machine (computer) that it can recognize and execute. A machine instruction consists of several bytes in memory that tell the processor to perform one machine operation. The processor looks at machine instructions in main
5 min read
Difference between CALL and JUMP instructionsIn assembly language as well as in low level programming CALL and JUMP are the two major control transfer instructions. Both instructions enable a program to go to different other parts of the code but both are different. CALL is mostly used to direct calls to subroutine or a function and regresses
5 min read
Simplified Instructional Computer (SIC)Simplified Instructional Computer (SIC) is a hypothetical computer that has hardware features that are often found in real machines. There are two versions of this machine: SIC standard ModelSIC/XE(extra equipment or expensive)Object programs for SIC can be properly executed on SIC/XE which is known
4 min read
Hardware architecture (parallel computing)Let's discuss about parallel computing and hardware architecture of parallel computing in this post. Note that there are two types of computing but we only learn parallel computing here. As we are going to learn parallel computing for that we should know following terms. Era of computing - The two f
3 min read
Computer Architecture | Flynn's taxonomyParallel computing is a computing paradigm where jobs are broken into discrete parts that can be executed concurrently. Each part is further broken down into a series of instructions. Instructions from each part execute simultaneously on different CPUs. Parallel systems deal with the simultaneous us
5 min read
Evolution of Generation of ComputersThe generation of computers refers to the progression of computer technology over time, marked by key advancements in hardware and software. These advancements are divided into five generations, each defined by improvements in processing power, size, efficiency, and overall capabilities. Starting wi
6 min read
Computer Organization | Amdahl's law and its proofIt is named after computer scientist Gene Amdahl( a computer architect from IBM and Amdahl corporation) and was presented at the AFIPS Spring Joint Computer Conference in 1967. It is also known as Amdahl's argument. It is a formula that gives the theoretical speedup in latency of the execution of a
6 min read
ALU, dataâ€Âpath and control unit
Instruction pipelining
Computer Organization and Architecture | Pipelining | Set 1 (Execution, Stages and Throughput)Pipelining is a technique used in modern processors to improve performance by executing multiple instructions simultaneously. It breaks down the execution of instructions into several stages, where each stage completes a part of the instruction. These stages can overlap, allowing the processor to wo
9 min read
Computer Organization and Architecture | Pipelining | Set 2 (Dependencies and Data Hazard)Please see Set 1 for Execution, Stages and Performance (Throughput) and Set 3 for Types of Pipeline and Stalling. Dependencies in a pipelined processor There are mainly three types of dependencies possible in a pipelined processor. These are : 1) Structural Dependency 2) Control Dependency 3) Data D
6 min read
Computer Organization and Architecture | Pipelining | Set 3 (Types and Stalling)Please see Set 1 for Execution, Stages and Performance (Throughput) and Set 2 for Dependencies and Data Hazard. Types of pipeline Uniform delay pipeline In this type of pipeline, all the stages will take same time to complete an operation. In uniform delay pipeline, Cycle Time (Tp) = Stage Delay If
3 min read
Computer Organization | Different Instruction CyclesIntroduction : Prerequisite - Execution, Stages and Throughput Registers Involved In Each Instruction Cycle: Memory address registers(MAR) : It is connected to the address lines of the system bus. It specifies the address in memory for a read or write operation.Memory Buffer Register(MBR) : It is co
11 min read
Performance of Computer in Computer OrganizationIn computer organization, performance refers to the speed and efficiency at which a computer system can execute tasks and process data. A high-performing computer system is one that can perform tasks quickly and efficiently while minimizing the amount of time and resources required to complete these
5 min read
Computer Organization | Micro-OperationIn computer organization, a micro-operation refers to the smallest tasks performed by the CPU's control unit. These micro-operations helps to execute complex instructions. They involve simple tasks like moving data between registers, performing arithmetic calculations, or executing logic operations.
3 min read
RISC and CISC in Computer OrganizationRISC is the way to make hardware simpler whereas CISC is the single instruction that handles multiple work. In this article, we are going to discuss RISC and CISC in detail as well as the Difference between RISC and CISC, Let's proceed with RISC first. Reduced Instruction Set Architecture (RISC) The
5 min read
Cache Memory
Memory Hierarchy Design and its CharacteristicsIn the Computer System Design, Memory Hierarchy is an enhancement to organize the memory such that it can minimize the access time. The Memory Hierarchy was developed based on a program behavior known as locality of references (same data or nearby data is likely to be accessed again and again). The
6 min read
Cache Memory in Computer OrganizationCache memory is a small, high-speed storage area in a computer. It stores copies of the data from frequently used main memory locations. There are various independent caches in a CPU, which store instructions and data. The most important use of cache memory is that it is used to reduce the average t
11 min read
Cache Organization | Set 1 (Introduction)Cache is close to CPU and faster than main memory. But at the same time is smaller than main memory. The cache organization is about mapping data in memory to a location in cache. A Simple Solution: One way to go about this mapping is to consider last few bits of long memory address to find small ca
3 min read
Computer Organization | Locality and Cache friendly codeCaches are the faster memories that are built to deal with the Processor-Memory gap in data read operation, i.e. the time difference in a data read operation in a CPU register and that in the main memory. Data read operation in registers is generally 100 times faster than in the main memory and it k
7 min read
Difference Between CPU Cache and TLBThe CPU Cache and Translation Lookaside Buffer (TLB) are two important microprocessor hardware components that improve system performance, although they have distinct functions. Even though some people may refer to TLB as a kind of cache, it's important to recognize the different functions they serv
4 min read
Read and Write operations in MemoryA memory unit stores binary information in groups of bits called words. Data input lines provide the information to be stored into the memory, Data output lines carry the information out from the memory. The control lines Read and write specifies the direction of transfer of data. Basically, in the
3 min read
Memory InterleavingPrerequisite - Virtual Memory Abstraction is one of the most important aspects of computing. It is a widely implemented Practice in the Computational field. Memory Interleaving is less or More an Abstraction technique. Though it's a bit different from Abstraction. It is a Technique that divides memo
3 min read
Introduction to memory and memory unitsMemory is required to save data and instructions. Memory is divided into cells, and they are stored in the storage space present in the computer. Every cell has its unique location/address. Memory is very essential for a computer as this is the way it becomes somewhat more similar to a human brain.
11 min read
Random Access Memory (RAM) and Read Only Memory (ROM)Memory is a fundamental component of computing systems, essential for performing various tasks efficiently. It plays a crucial role in how computers operate, influencing speed, performance, and data management. In the realm of computer memory, two primary types stand out: Random Access Memory (RAM)
8 min read
Different Types of RAM (Random Access Memory )In the computer world, memory plays an important component in determining the performance and efficiency of a system. In between various types of memory, Random Access Memory (RAM) stands out as a necessary component that enables computers to process and store data temporarily. In this article, we w
8 min read
Difference between RAM and ROMMemory is an important part of the Computer which is responsible for storing data and information on a temporary or permanent basis. Memory can be classified into two broad categories: Primary Memory Secondary Memory What is Primary Memory? Primary Memory is a type of Computer Memory that the Prepro
7 min read
I/O interface (Interrupt and DMA mode)
I/O Interface (Interrupt and DMA Mode)The method that is used to transfer information between internal storage and external I/O devices is known as I/O interface. The CPU is interfaced using special communication links by the peripherals connected to any computer system. These communication links are used to resolve the differences betw
6 min read
Introduction of Input-Output ProcessorThe DMA mode of data transfer reduces the CPU's overhead when handling I/O operations. It also allows parallel processing between CPU and I/O operations. This parallelism is necessary to avoid the wastage of valuable CPU time when handling I/O devices whose speeds are much slower as compared to CPU.
5 min read
Kernel I/O Subsystem in Operating SystemThe kernel provides many services related to I/O. Several services such as scheduling, caching, spooling, device reservation, and error handling - are provided by the kernel's I/O subsystem built on the hardware and device-driver infrastructure. The I/O subsystem is also responsible for protecting i
7 min read
Memory Mapped I/O and Isolated I/OCPU needs to communicate with the various memory and input-output devices (I/O). Data between the processor and these devices flow with the help of the system bus. There are three ways in which system bus can be allotted to them:Separate set of address, control and data bus to I/O and memory.Have co
5 min read
BUS Arbitration in Computer OrganizationIntroduction : In a computer system, multiple devices, such as the CPU, memory, and I/O controllers, are connected to a common communication pathway, known as a bus. In order to transfer data between these devices, they need to have access to the bus. Bus arbitration is the process of resolving conf
7 min read
Priority Interrupts | (S/W Polling and Daisy Chaining)In I/O Interface (Interrupt and DMA Mode), we have discussed the concept behind the Interrupt-initiated I/O. To summarize, when I/O devices are ready for I/O transfer, they generate an interrupt request signal to the computer. The CPU receives this signal, suspends the current instructions it is exe
5 min read
Computer Organization | Asynchronous input output synchronizationIntroduction : Asynchronous input/output (I/O) synchronization is a technique used in computer organization to manage the transfer of data between the central processing unit (CPU) and external devices. In asynchronous I/O synchronization, data transfer occurs at an unpredictable rate, with no fixed
7 min read
Introduction of Ports in ComputersA port is basically a physical docking point which is basically used to connect the external devices to the computer, or we can say that A port act as an interface between the computer and the external devices, e.g., we can connect hard drives, printers to the computer with the help of ports. Featur
3 min read
Clusters In Computer OrganisationA cluster is a set of loosely or tightly connected computers working together as a unified computing resource that can create the illusion of being one machine. Computer clusters have each node set to perform the same task, controlled and produced by the software. Clustered Operating Systems work si
7 min read
Human - Computer interaction through the agesIntroduction - The advent of a technological marvel called the “computer†has revolutionized life in the twenty-first century. From IoT to self-driving cars to smart cities, computers have percolated through the fabric of society. Unsurprisingly the methods with which we interact with computers have
4 min read