The Relational Model is a fundamental concept in Database Management Systems (DBMS) that organizes data into tables, also known as relations. This model simplifies data storage, retrieval, and management by using rows and columns. Codd’s Rules, introduced by Dr. Edgar F. Codd, define the principles a database must follow to qualify as a true relational database.
These rules ensure data consistency, integrity, and ease of access, making them essential for efficient database design and management. Its other key features are as follows:
- Simplicity: Conveying simplicity in implementation, simplifies the operations that one will want to perform on data.
- Linking: It uses primary and secondary keys to interlink two files or tables.
- Normalization: It utilizes the concept of normalization theory for designing non-redundant and efficient object-based data models.
- Data Processing: It utilizes Relational Algebra and Relational Calculus for manipulation of these relations. Many database languages have been developed having special features for handling relational data models.
What is Relational Model?
Relational Model is a key concept in Database Management Systems (DBMS) that organizes data in a structured and efficient way. It represents data and their relationships using tables. Each table has multiple columns, each with a unique name. These tables are also called relations. The relational model is widely used because it simplifies database management and ensures data accuracy.
It primarily uses SQL (Structured Query Language) to manage and query data stored in tables with predefined relationships. SQL is widely used because it offers a consistent and efficient way to interact with relational databases. NoSQL databases, although not part of the relational model, are often used as an alternative for managing unstructured or semi-structured data. They provide greater flexibility and scalability, making them ideal for large, fast-growing applications. However, relational databases with SQL remain popular for applications requiring strong consistency and complex queries.
Some of the most well-known Relational database include MySQL, PostgreSQL, MariaDB, Microsoft SQL Server, and Oracle Database.
Terminologies
Relations (Tables): It is the basic structure in which data is stored. Each relation is made up of rows and columns.
Example: The table above named Student, is a relation. It stores data about students using rows and columns.
Relational Schema: Schema represents the structure of a relation.
Example: Relational Schema of STUDENT relation can be represented as STUDENT(StudentID, Name, Age, Course).
Relational Instance: The set of values present in a relationship at a particular instance of time is known as a relational instance as shown in Table .
Attribute: Each relation is defined in terms of some properties, each of which is known as an attribute. or Each column shows an attribute of the data.
Example: StudentID, Name, Age, and Course are the attributes in this table.
The domain of an attribute: The possible values an attribute can take in a relation is called its domain.
Example: The domain of the Age column is valid ages like 21, 22, 23 etc.
The domain of the Course column includes valid courses like "Computer Science," "Mathematics," and "Physics."
Tuple: Each row of a relation is known as a tuple.
Example: STUDENT relation has 4 tuples.
Cardinality: Cardinality refers to the number of distinct values in a column compared to the total number of rows in a table.
Example: The Age column has 3 distinct values: 21, 22 and 23.
Degree (Arity): The degree of relation refers to total number of attribute a relation has. It is also known as Arity.
Example: The degree of this table is 4 because it has 4 columns: StudentID, Name, Age and Course.
Primary Key: The primary key is an attribute or a set of attributes that help to uniquely identify the tuples(records) in the relational table.
NULL values: Values of some attribute for some tuples may be unknown, missing, or undefined which are represented by NULL. Two NULL values in a relationship are considered different from each other.
STUDENT TABLE
Imagine a Student Table in a database:
| StudentID | Name | Age | Course |
|---|
| 1 | Vaibhav Garg | 21 | Computer Science |
| 2 | Komal Gupta | 22 | Mathematics |
| 3 | Varnika Gangwar | 21 | Physics |
| 4 | Shubhi Chandra | 23 | Computer Science |
- Relational Model can be represented as shown below:
STUDENT (StudNo, Sname, Special)
ENROLLMENT (StudNo, Subcode, marks)
SUBJECT (Subcode, Subname, Maxmarks, Faccode)
FACULTY (Faccode, Fname, Dept)
Read more about Relational Model.
RDBMS Vendors
There are several vendors that offer Relational Database Management Systems (RDBMS). Here are some of the most popular ones:
- Oracle: Oracle Database is one of the most widely used RDBMS products in the market. It is known for its robustness, scalability, and reliability. It is used by many large enterprises and is particularly well-suited for data warehousing and transaction processing.
- Microsoft: Microsoft SQL Server is a popular RDBMS used in Windows environments. It offers a range of features, including data mining, business intelligence, and reporting services.
- IBM: IBM DB2 is a popular RDBMS used in enterprise environments. It offers high availability, disaster recovery, and scalability features.
- MySQL: MySQL is an open-source RDBMS used by many small to medium-sized businesses. It is known for its ease of use, flexibility, and low cost.
- PostgreSQL: PostgreSQL is another popular open-source RDBMS. It is known for its scalability, reliability, and support for complex transactions.
- SAP: SAP HANA is an in-memory RDBMS that is designed for high-performance analytics and data processing. It is often used in enterprise environments for real-time reporting and business intelligence.
Relational Algebra
It is a procedural Language. It consists of a set of operators that can be performed on relations. Relational Algebra forms the basis for many other high-level data sub-languages like SQL and QBE.
Relational algebra has mainly 9 types of operators.
1. UNION (U): A and B are two relations. It displays total values (Attributes) in both relations. It avoids duplicate values in both relations. U symbol can be used.
Syntax:
A UNION B (or) A U B
Example:
A = { clerk, manager, salesman}
B = { president, clerk, manager}
A UNION B = {clerk, manager, salesman, president}
2. INTERSECTION (∩): A and B are two relations. It displays common elements in both relations. “∩” symbol can be used.
Syntax:
A INTERSECT B (or) A ∩ B
Example:
A = { clerk, manager, salesman}
B = { president, clerk, manager}
A INTERSECT B = { clerk, manager}
3. DIFFERENCE (─): A and B are two relations. It displays elements in relation A not in relation B.
Syntax:
A MINUS B (OR) A ─ B
Example:
A = { clerk, manager, salesman}
B = { president, clerk, manager}
A MINUS B = {salesman}
4. CARTESIAN PRODUCT(X): A and B are two relations. It has a new relation consisting of all pair wises combinations of all elements in A and B. The relation A has “m” elements and relation B has “n” elements, then the resultant relation will be “ m * n “.
Syntax:
A TIMES B (OR) A X B
Example:
A = { clerk, manager, salesman}
B = { president, clerk, manager}
A TIMES B = { (clerk, president),
(clerk, clerk),(clerk, manager),
(manager, president), (manager, clerk),
(manager, manager),(salesman, president),
(salesman, clerk), (salesman, manager) }5. SELECTION (σ): Selection operation chooses the subset of tuples from the relation that satisfies the given condition.
In general SELECT operation is denoted by
(σ)θ(R)
(σ)(Sigma): SELECT operator
θ: Selection condition
R: Relation or relational algebra expression.
In general the select condition is a Boolean condition (i.e. an expression using logical connective) of terms that have the form attribute1 OP attribute2 where OP is the comparison operators <,>,=,>= etc.
Syntax:
σ condition (relation name)
6. PROJECTION (π): It displays some specified columns in a relation. “π” operator can be used to select some specified columns in a relation. It selects tuples that satisfy the given predicate from a relation. It displays some specified columns by using some conditions.
Syntax:
π(col1,col2…) Relation Name
Example:
π(sno, sname, total) MARKS
7. JOIN( ): It combines two or more relations. It can be mainly divided into mainly 4 types. These are mainly
8. DIVIDE (÷): It divides the tuple from one relation to another relation
Syntax:
A DIVIDE B (OR) A ÷ B
Example:
A = { clerk, manager, salesman}
B = { clerk, manager}
A DIVIDE B = {salesman} 9. RENAME(ρ): It gives another name to the relation.
Syntax:
ρ(OLD RELATION, NEW RELATION)
Example:
ρ(STUDENT, MARKS)
It changes the “student” relation to “Marks” relation.
It also renames the specified column.
It changes the old-column name to new-column name.
Features of the Relational Model and Codd's Rules
- Tables/Relations: The basic building block of the relational model is the table or relation, which represents a collection of related data. Each table consists of columns, also known as attributes or fields, and rows, also known as tuples or records.
- Primary Keys: In the relational model, each row in a table must have a unique identifier, which is known as the primary key. This ensures that each row is unique and can be accessed and manipulated easily.
- Foreign Keys: Foreign keys are used to link tables together and enforce referential integrity. They ensure that data in one table is consistent with data in another table.
- Normalization: The process of organizing data into tables and eliminating redundancy is known as normalization. Normalization is important in the relational model because it helps to ensure that data is consistent and easy to maintain.
- Codd's Rules: Codd's Rules are a set of 12 rules that define the characteristics of a true relational DBMS. These rules ensure that the DBMS is consistent, reliable, and easy to use.
- Atomicity, Consistency, Isolation, Durability (ACID): The ACID properties are a set of properties that ensure that transactions are processed reliably in the relational model. Transactions are sets of operations that are executed as a single unit, ensuring that data is consistent and accurate.
Advantages of Relational Algebra
Relational Algebra is a formal language used to specify queries to retrieve data from a relational database. It has several advantages that make it a popular choice for managing and manipulating data. Here are some of the advantages of Relational Algebra:
- Simplicity: Relational Algebra provides a simple and easy-to-understand set of operators that can be used to manipulate data. It is based on a set of mathematical concepts and principles, which makes it easy to learn and use.
- Formality: Relational Algebra is a formal language that provides a standardized and rigorous way of expressing queries. This makes it easier to write and debug queries, and also ensures that queries are correct and consistent.
- Abstraction: Relational Algebra provides a high-level abstraction of the underlying database structure, which makes it easier to work with large and complex databases. It allows users to focus on the logical structure of the data, rather than the physical storage details.
- Portability: Relational Algebra is independent of any specific database management system, which means that queries can be easily ported to other systems. This makes it easy to switch between different databases or vendors without having to rewrite queries.
- Efficiency: Relational Algebra is optimized for efficiency and performance, which means that queries can be executed quickly and with minimal resources. This is particularly important for large and complex databases, where performance is critical.
- Extensibility: Relational Algebra provides a flexible and extensible framework that can be extended with new operators and functions. This allows developers to customize and extend the language to meet their specific needs.
Disadvantages of Relational Algebra
While Relational Algebra has many advantages, it also has some limitations and disadvantages that should be considered when using it. Here are some of the disadvantages of Relational Algebra:
- Limited Expressiveness: Relational Algebra has a limited set of operators, which can make it difficult to express certain types of queries. It may be necessary to use more advanced techniques, such as subqueries or joins, to express complex queries.
- Lack of Flexibility: Relational Algebra is designed for use with relational databases, which means that it may not be well-suited for other types of data storage or management systems. This can limit its flexibility and applicability in certain contexts.
- Performance Limitations: While Relational Algebra is optimized for efficiency and performance, it may not be able to handle large or complex datasets. Queries can become slow and resource-intensive when dealing with large amounts of data or complex queries.
- Limited Data Types: Relational Algebra is designed for use with simple data types, such as integers, strings, and dates. It may not be well-suited for more complex data types, such as multimedia files or spatial data.
- Lack of Integration: Relational Algebra is often used in conjunction with other programming languages and tools, which can create integration challenges. It may require additional programming effort to integrate Relational Algebra with other systems and tools.
Relational Algebra is a powerful and useful tool for managing and manipulating data in relational databases, it has some limitations and disadvantages that should be carefully considered when using it.
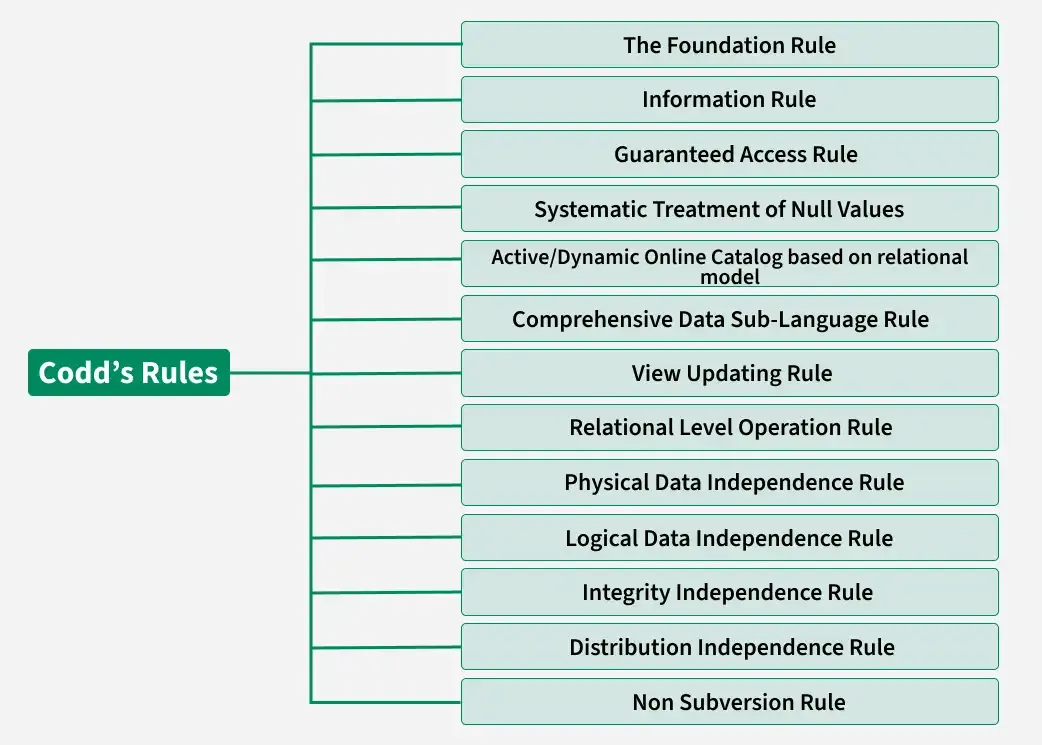
Codd's Twelve Rules of Relational Database
Codd rules were proposed by E.F. Codd which should be satisfied by the relational model. Codd's Rules are basically used to check whether DBMS has the quality to become Relational Database Management System (RDBMS).These rules set basic guidelines to ensure data is stored and managed in a clear, consistent, and reliable way. But, it is rare to find that any product has fulfilled all the rules of Codd.
They generally follow the 8-9 rules of Codd. E.F. Codd has proposed 13 rules which are popularly known as Codd's 12 rules. These rules are stated as follows:
- Rule 0: Foundation Rule- For any system that is advertised as, or claimed to be, a relational database management system, that system must be able to manage databases entirely through its relational capabilities.
- Rule 1: Information Rule- Data stored in the Relational model must be a value of some cell of a table.
- Rule 2: Guaranteed Access Rule- Every data element must be accessible by the table name, its primary key, and the name of the attribute whose value is to be determined.
- Rule 3: Systematic Treatment of NULL values- NULL value in the database must only correspond to missing, unknown, or not applicable values.
- Rule 4: Active Online Catalog- The structure of the database must be stored in an online catalog that can be queried by authorized users.
- Rule 5: Comprehensive Data Sub-language Rule- A database should be accessible by a language supported for definition, manipulation, and transaction management operation.
- Rule 6: View Updating Rule- Different views created for various purposes should be automatically updatable by the system.
- Rule 7: High-level insert, update and delete rule- Relational Model should support insert, delete, update, etc. operations at each level of relations. Also, set operations like Union, Intersection, and minus should be supported.
- Rule 8: Physical data independence- Any modification in the physical location of a table should not enforce modification at the application level.
- Rule 9: Logical data independence- Any modification in the logical or conceptual schema of a table should not enforce modification at the application level. For example, merging two tables into one should not affect the application accessing it which is difficult to achieve.
- Rule 10: Integrity Independence- Integrity constraints modified at the database level should not enforce modification at the application level.
- Rule 11: Distribution Independence- Distribution of data over various locations should not be visible to end-users.
- Rule 12: Non-Subversion Rule- Low-level access to data should not be able to bypass the integrity rule to change data.
 Codd's Rules
Codd's RulesGATE Question-2012
Conclusion
The relational model evolved by E.F. Codd, brought a revolution in handling data because it showed how data could be stored in two-dimensional tables for easier manipulation and interaction. Codd designed twelve rules that would set guidelines to maintain integrity, consistency, and scalability in the RDBMS. Few commercial products follow these rules entirely; however, these are something core to database design. Relational databases are still the most widely used for their ease, simplicity, and power of querying. As technology has evolved, Codd's principles remain guiding factors in developing scalable, secure, efficient systems of data management and are a core ingredient of modern database solutions.
Similar Reads
DBMS Tutorial – Learn Database Management System Database Management System (DBMS) is a software used to manage data from a database. A database is a structured collection of data that is stored in an electronic device. The data can be text, video, image or any other format.A relational database stores data in the form of tables and a NoSQL databa
7 min read
Basic of DBMS
Introduction of DBMS (Database Management System)A Database Management System (DBMS) is a software solution designed to efficiently manage, organize, and retrieve data in a structured manner. It serves as a critical component in modern computing, enabling organizations to store, manipulate, and secure their data effectively. From small application
8 min read
History of DBMSThe first database management systems (DBMS) were created to handle complex data for businesses in the 1960s. These systems included Charles Bachman's Integrated Data Store (IDS) and IBM's Information Management System (IMS). Databases were first organized into tree-like structures using hierarchica
7 min read
DBMS Architecture 1-level, 2-Level, 3-LevelA database stores important information that needs to be accessed quickly and securely. Choosing the right DBMS architecture is essential for organizing, managing, and maintaining the data efficiently. It defines how users interact with the database to read, write, or update information. The schema
7 min read
Difference between File System and DBMSA file system and a DBMS are two kinds of data management systems that are used in different capacities and possess different characteristics. A File System is a way of organizing files into groups and folders and then storing them in a storage device. It provides the media that stores data as well
6 min read
Entity Relationship Model
Introduction of ER ModelThe Entity-Relationship Model (ER Model) is a conceptual model for designing a databases. This model represents the logical structure of a database, including entities, their attributes and relationships between them. Entity: An objects that is stored as data such as Student, Course or Company.Attri
10 min read
Structural Constraints of Relationships in ER ModelStructural constraints, within the context of Entity-Relationship (ER) modeling, specify and determine how the entities take part in the relationships and this gives an outline of how the interactions between the entities can be designed in a database. Two primary types of constraints are cardinalit
5 min read
Generalization, Specialization and Aggregation in ER ModelUsing the ER model for bigger data creates a lot of complexity while designing a database model, So in order to minimize the complexity Generalization, Specialization, and Aggregation were introduced in the ER model. These were used for data abstraction. In which an abstraction mechanism is used to
4 min read
Introduction of Relational Model and Codd Rules in DBMSThe Relational Model is a fundamental concept in Database Management Systems (DBMS) that organizes data into tables, also known as relations. This model simplifies data storage, retrieval, and management by using rows and columns. Codd’s Rules, introduced by Dr. Edgar F. Codd, define the principles
14 min read
Types of Keys in Relational Model (Candidate, Super, Primary, Alternate and Foreign)In the context of a relational database, Keys are one of the basic requirements of a relational database model. keys are fundamental components that ensure data integrity, uniqueness, and efficient access. It is widely used to identify the tuples(rows) uniquely in the table. We also use keys to set
8 min read
Mapping from ER Model to Relational ModelConverting an Entity-Relationship (ER) diagram to a Relational Model is a crucial step in database design. The ER model represents the conceptual structure of a database, while the Relational Model is a physical representation that can be directly implemented using a Relational Database Management S
7 min read
Strategies for Schema design in DBMSThere are various strategies that are considered while designing a schema. Most of these strategies follow an incremental approach that is, they must start with some schema constructs derived from the requirements and then they incrementally modify, refine, or build on them. In this article, let's d
7 min read
Relational Model
Introduction of Relational Algebra in DBMSRelational Algebra is a formal language used to query and manipulate relational databases, consisting of a set of operations like selection, projection, union, and join. It provides a mathematical framework for querying databases, ensuring efficient data retrieval and manipulation. Relational algebr
9 min read
SQL Joins (Inner, Left, Right and Full Join)SQL joins are fundamental tools for combining data from multiple tables in relational databases. Joins allow efficient data retrieval, which is essential for generating meaningful observations and solving complex business queries. Understanding SQL join types, such as INNER JOIN, LEFT JOIN, RIGHT JO
5 min read
Join operation Vs Nested query in DBMSThe growth of technology and automation coupled with exponential amounts of data has led to the importance and omnipresence of databases which, simply put, are organized collections of data. Considering a naive approach, one can theoretically keep all the data in one large table, however that increa
5 min read
Tuple Relational Calculus (TRC) in DBMSTuple Relational Calculus (TRC) is a non-procedural query language used in relational database management systems (RDBMS) to retrieve data from tables. TRC is based on the concept of tuples, which are ordered sets of attribute values that represent a single row or record in a database table. TRC is
4 min read
Domain Relational Calculus in DBMSDomain Relational Calculus is a non-procedural query language equivalent in power to Tuple Relational Calculus. Domain Relational Calculus provides only the description of the query but it does not provide the methods to solve it. In Domain Relational Calculus, a query is expressed as, { < x1, x2
2 min read
Relational Algebra
Introduction of Relational Algebra in DBMSRelational Algebra is a formal language used to query and manipulate relational databases, consisting of a set of operations like selection, projection, union, and join. It provides a mathematical framework for querying databases, ensuring efficient data retrieval and manipulation. Relational algebr
9 min read
SQL Joins (Inner, Left, Right and Full Join)SQL joins are fundamental tools for combining data from multiple tables in relational databases. Joins allow efficient data retrieval, which is essential for generating meaningful observations and solving complex business queries. Understanding SQL join types, such as INNER JOIN, LEFT JOIN, RIGHT JO
5 min read
Join operation Vs Nested query in DBMSThe growth of technology and automation coupled with exponential amounts of data has led to the importance and omnipresence of databases which, simply put, are organized collections of data. Considering a naive approach, one can theoretically keep all the data in one large table, however that increa
5 min read
Tuple Relational Calculus (TRC) in DBMSTuple Relational Calculus (TRC) is a non-procedural query language used in relational database management systems (RDBMS) to retrieve data from tables. TRC is based on the concept of tuples, which are ordered sets of attribute values that represent a single row or record in a database table. TRC is
4 min read
Domain Relational Calculus in DBMSDomain Relational Calculus is a non-procedural query language equivalent in power to Tuple Relational Calculus. Domain Relational Calculus provides only the description of the query but it does not provide the methods to solve it. In Domain Relational Calculus, a query is expressed as, { < x1, x2
2 min read
Functional Dependencies & Normalization
Functional Dependency and Attribute ClosureFunctional dependency and attribute closure are essential for maintaining data integrity and building effective, organized, and normalized databases.Functional DependencyA functional dependency A->B in a relation holds if two tuples having the same value of attribute A must have the same value fo
5 min read
Armstrong's Axioms in Functional Dependency in DBMSArmstrong's Axioms refer to a set of inference rules, introduced by William W. Armstrong, that are used to test the logical implication of functional dependencies. Given a set of functional dependencies F, the closure of F (denoted as F+) is the set of all functional dependencies logically implied b
4 min read
Canonical Cover of Functional Dependencies in DBMSManaging a large set of functional dependencies can result in unnecessary computational overhead. This is where the canonical cover becomes useful. The canonical cover of a set of functional dependencies F is a simplified version of F that retains the same closure as the original set, ensuring no re
7 min read
Normal Forms in DBMSIn the world of database management, Normal Forms are important for ensuring that data is structured logically, reducing redundancy, and maintaining data integrity. When working with databases, especially relational databases, it is critical to follow normalization techniques that help to eliminate
7 min read
The Problem of Redundancy in DatabaseRedundancy means having multiple copies of the same data in the database. This problem arises when a database is not normalized. Suppose a table of student details attributes is: student ID, student name, college name, college rank, and course opted. Student_ID Name Contact College Course Rank 100Hi
6 min read
Lossless Join and Dependency Preserving DecompositionDecomposition of a relation is done when a relation in a relational model is not in appropriate normal form. Relation R is decomposed into two or more relations if decomposition is lossless join as well as dependency preserving. Lossless Join DecompositionIf we decompose a relation R into relations
4 min read
Denormalization in DatabasesDenormalization focuses on combining multiple tables to make queries execute quickly. It adds redundancies in the database though. In this article, we’ll explore Denormalization and how it impacts database design. This method can help us to avoid costly joins in a relational database made during nor
6 min read
Transactions & Concurrency Control
ACID Properties in DBMSIn the world of DBMS, transactions are fundamental operations that allow us to modify and retrieve data. However, to ensure the integrity of a database, it is important that these transactions are executed in a way that maintains consistency, correctness, and reliability. This is where the ACID prop
8 min read
Types of Schedules in DBMSSchedule, as the name suggests, is a process of lining the transactions and executing them one by one. When there are multiple transactions that are running in a concurrent manner and the order of operation is needed to be set so that the operations do not overlap each other, Scheduling is brought i
7 min read
Recoverability in DBMSRecoverability is a critical feature of database systems. It ensures that after a failure, the database returns to a consistent state by permanently saving committed transactions and rolling back uncommitted ones. It relies on transaction logs to undo or redo changes as needed. This is crucial in mu
6 min read
Implementation of Locking in DBMSLocking protocols are used in database management systems as a means of concurrency control. Multiple transactions may request a lock on a data item simultaneously. Hence, we require a mechanism to manage the locking requests made by transactions. Such a mechanism is called a Lock Manager. It relies
5 min read
Deadlock in DBMSIn a Database Management System (DBMS), a deadlock occurs when two or more transactions are waiting indefinitely for one another to release resources (such as locks on tables, rows, or other database objects). This results in a situation where none of the transactions can proceed, effectively bringi
8 min read
Starvation in DBMSStarvation in DBMS is a problem that happens when some processes are unable to get the resources they need because other processes keep getting priority. This can happen in situations like locking or scheduling, where some processes keep getting the resources first, leaving others waiting indefinite
8 min read
Advanced DBMS
Indexing in Databases - Set 1Indexing is a crucial technique used in databases to optimize data retrieval operations. It improves query performance by minimizing disk I/O operations, thus reducing the time it takes to locate and access data. Essentially, indexing allows the database management system (DBMS) to locate data more
8 min read
Introduction of B-TreeA B-Tree is a specialized m-way tree designed to optimize data access, especially on disk-based storage systems. In a B-Tree of order m, each node can have up to m children and m-1 keys, allowing it to efficiently manage large datasets.The value of m is decided based on disk block and key sizes.One
8 min read
Introduction of B+ TreeB + Tree is a variation of the B-tree data structure. In a B + tree, data pointers are stored only at the leaf nodes of the tree. In this tree, structure of a leaf node differs from the structure of internal nodes. The leaf nodes have an entry for every value of the search field, along with a data p
8 min read
Bitmap Indexing in DBMSBitmap Indexing is a data indexing technique used in database management systems (DBMS) to improve the performance of read-only queries that involve large datasets. It involves creating a bitmap index, which is a data structure that represents the presence or absence of data values in a table or col
8 min read
Inverted IndexAn Inverted Index is a data structure used in information retrieval systems to efficiently retrieve documents or web pages containing a specific term or set of terms. In an inverted index, the index is organized by terms (words), and each term points to a list of documents or web pages that contain
7 min read
SQL Queries on Clustered and Non-Clustered IndexesIndexes in SQL play a pivotal role in enhancing database performance by enabling efficient data retrieval without scanning the entire table. The two primary types of indexes Clustered Index and Non-Clustered Index serve distinct purposes in optimizing query performance. In this article, we will expl
7 min read
File Organization in DBMS - Set 1A database consists of a huge amount of data. The data is grouped within a table in RDBMS, and each table has related records. A user can see that the data is stored in the form of tables, but in actuality, this huge amount of data is stored in physical memory in the form of files. What is a File?A
6 min read
DBMS Practice