Lock Based Concurrency Control Protocol in DBMS
Last Updated : 10 Jun, 2025
In a DBMS, lock-based concurrency control is a method used to manage how multiple transactions access the same data. This protocol ensures data consistency and integrity when multiple users interact with the database simultaneously.
This method uses locks to manage access to data, ensuring transactions don’t clash and everything runs smoothly when multiple transactions happen at the same time. In this article, we’ll take a closer look at how the Lock-Based Protocol works.
What is a Lock?
A lock is a control mechanism used in databases to manage concurrent access to data items. It is a variable associated with a data item that indicates whether it is in use. Locks prevent multiple transactions from accessing the same data simultaneously, ensuring data integrity, consistency, and preventing conflicts during concurrent operations.
Lock Based Protocols
Lock-Based Protocols in DBMS ensure that a transaction cannot read or write data until it gets the necessary lock. Here's how they work:
- These protocols prevent concurrency issues by allowing only one transaction to access a specific data item at a time.
- Locks help multiple transactions work together smoothly by managing access to the database items.
- Locking is a common method used to maintain the serializability of transactions.
- A transaction must acquire a read lock or write lock on a data item before performing any read or write operations on it.
Types of Lock
- Shared Lock (S): Shared Lock is also known as Read-only lock. As the name suggests it can be shared between transactions because while holding this lock the transaction does not have the permission to update data on the data item. S-lock is requested using lock-S instruction.
- Exclusive Lock (X): Data item can be both read as well as written. This is Exclusive and cannot be held simultaneously on the same data item. X-lock is requested using lock-X instruction.
Read more about Types of Locks.
Rules of Locking
The basic rules for Locking are given below:
Read Lock (or) Shared Lock(S)
- If a Transaction has a Read lock on a data item, it can read the item but not update it.
- If a transaction has a Read lock on the data item, other transaction can obtain Read Lock on the data item but no Write Locks.
- So, the Read Lock is also called a Shared Lock.
Write Lock (or) Exclusive Lock (X)
- If a transaction has a write Lock on a data item, it can both read and update the data item.
- If a transaction has a write Lock on the data item, then other transactions cannot obtain either a Read lock or write lock on the data item.
- So, the Write Lock is also known as Exclusive Lock.
Lock Compatibility Matrix
- A transaction can acquire a lock on a data item only if the requested lock is compatible with existing locks held by other transactions.
- Shared Locks (S): Multiple transactions can hold shared locks on the same data item simultaneously.
- Exclusive Lock (X): If a transaction holds an exclusive lock on a data item, no other transaction can hold any type of lock on that item.
- If a requested lock is not compatible, the requesting transaction must wait until all incompatible locks are released by other transactions.
- Once the incompatible locks are released, the requested lock is granted.
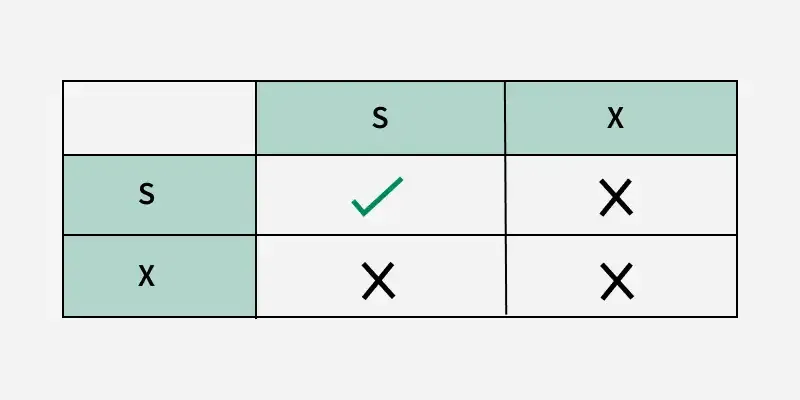 Compatibility Matrix
Compatibility MatrixConcurrency Control Protocols
Concurrency Control Protocols are the methods used to manage multiple transactions happening at the same time. They ensure that transactions are executed safely without interfering with each other, maintaining the accuracy and consistency of the database.
These protocols prevent issues like data conflicts, lost updates or inconsistent data by controlling how transactions access and modify data.
Types of Lock-Based Protocols
1. Simplistic Lock Protocol
It is the simplest method for locking data during a transaction. Simple lock-based protocols enable all transactions to obtain a lock on the data before inserting, deleting, or updating it. It will unlock the data item once the transaction is completed.
Example:
Consider a database with a single data item X = 10.
Transactions:
- T1: Wants to read and update
X. - T2: Wants to read
X.
Steps:
- T1 requests an exclusive lock on
X to update its value. The lock is granted.- T1 reads
X = 10 and updates it to X = 20.
- T2 requests a shared lock on
X to read its value. Since T1 is holding an exclusive lock, T2 must wait. - T1 completes its operation and releases the lock.
- T2 now gets the shared lock and reads the updated value
X = 20.
This example shows how simplistic lock protocols handle concurrency but do not prevent problems like deadlocks or limits concurrency.
2. Pre-Claiming Lock Protocol
The Pre-Claiming Lock Protocol requires a transaction to request all needed locks in advance, before execution begins. If all locks are granted, the transaction proceeds; otherwise, it rolls back and waits. This approach prevents deadlocks by ensuring a transaction only runs when it can lock all required data items upfront.
Example:
Consider two transactions T1 and T2 and two data items, X and Y:
- Transaction T1 declares that it needs:
- A write lock on
X. - A read lock on
Y.
Since both locks are available, the system grants them. T1 starts execution:- It updates
X. - It reads the value of
Y.
- While T1 is executing, Transaction T2 declares that it needs:However, since T1 already holds a write lock on
X, T2's request is denied. T2 must wait until T1 completes its operations and releases the locks. - Once T1 finishes, it releases the locks on
X and Y. The system now grants the read lock on X to T2, allowing it to proceed.
This method is simple but may lead to inefficiency in systems with a high number of transactions.
3. Two-phase locking (2PL)
A transaction is said to follow the Two-Phase Locking protocol if Locking and Unlocking can be done in two phases :
- Growing Phase: New locks on data items may be acquired but none can be released.
- Shrinking Phase: Existing locks may be released but no new locks can be acquired.
For more detail refer the article Two-phase locking (2PL).
4. Strict Two-Phase Locking Protocol
Strict Two-Phase Locking requires that in addition to the 2-PL all Exclusive(X) locks held by the transaction be released until after the Transaction Commits.
For more details refer the article Strict Two-Phase Locking Protocol.
Problem With Simple Locking
Consider the Partial Schedule:
| S.No | T1 | T2 |
|---|
| 1 | lock-X(B) | |
| 2 | read(B) | |
| 3 | B:=B-50 | |
| 4 | write(B) | |
| 5 | | lock-S(A) |
| 6 | | read(A) |
| 7 | | lock-S(B) |
| 8 | lock-X(A) | |
| 9 | ...... | ...... |
1. Deadlock
In the given execution scenario, T1 holds an exclusive lock on B, while T2 holds a shared lock on A. At Statement 7, T2 requests a lock on B, and at Statement 8, T1 requests a lock on A. This situation creates a deadlock, as both transactions are waiting for resources held by the other, preventing either from proceeding with their execution.
2. Starvation
Starvation is also possible if concurrency control manager is badly designed. For example: A transaction may be waiting for an X-lock on an item, while a sequence of other transactions request and are granted an S-lock on the same item. This may be avoided if the concurrency control manager is properly designed.
Similar Reads
Structured Query Language (SQL) Structured Query Language is a standard Database language that is used to create, maintain, and retrieve the relational database. In this article, we will discuss this in detail about SQL. Following are some interesting facts about SQL. Let's focus on that. SQL is case insensitive. But it is a recom
6 min read
Inner Join vs Outer Join Inner Join and Outer Join are the types of join. The inner join has the work to return the common rows between the two tables, whereas the Outer Join has the work of returning the work of the inner join in addition to the rows that are not matched. Let's discuss both of them in detail in this articl
9 min read
Having vs Where Clause in SQL In SQL, filtering data is important for extracting meaningful insights from large datasets. While both the WHERE and HAVING clauses allow us to filter data, they serve distinct purposes and operate at different stages of the query execution process. Understanding the difference between these clauses
4 min read
Concurrency Control in DBMS In a database management system (DBMS), allowing transactions to run concurrently has significant advantages, such as better system resource utilization and higher throughput. However, it is crucial that these transactions do not conflict with each other. The ultimate goal is to ensure that the data
7 min read
Database Recovery Techniques in DBMS Database Systems like any other computer system, are subject to failures but the data stored in them must be available as and when required. When a database fails it must possess the facilities for fast recovery. It must also have atomicity i.e. either transactions are completed successfully and com
11 min read
ACID Properties in DBMS In the world of DBMS, transactions are fundamental operations that allow us to modify and retrieve data. However, to ensure the integrity of a database, it is important that these transactions are executed in a way that maintains consistency, correctness, and reliability. This is where the ACID prop
8 min read
Why recovery is needed in DBMS Basically, whenever a transaction is submitted to a DBMS for execution, the operating system is responsible for making sure or to be confirmed that all the operations which need to be performed in the transaction have been completed successfully and their effect is either recorded in the database or
6 min read
Types of Schedules in DBMS Schedule, as the name suggests, is a process of lining the transactions and executing them one by one. When there are multiple transactions that are running in a concurrent manner and the order of operation is needed to be set so that the operations do not overlap each other, Scheduling is brought i
7 min read
Conflict Serializability in DBMS A schedule is a sequence in which operations (read, write, commit, abort) from multiple transactions are executed in a database. Serial or one by one execution of schedules has less resource utilization and low throughput. To improve it, two or more transactions are run concurrently. Conflict Serial
5 min read
Precedence Graph for Testing Conflict Serializability in DBMS A Precedence Graph or Serialization Graph is used commonly to test the Conflict Serializability of a schedule. It is a directed Graph (V, E) consisting of a set of nodes V = {T1, T2, T3..........Tn} and a set of directed edges E = {e1, e2, e3..................em}. The graph contains one node for eac
6 min read