Multiple Granularity Locking in DBMS
Last Updated : 10 Jun, 2025
The various Concurrency Control schemes have used different methods and every individual data item is the unit on which synchronization is performed. A certain drawback of this technique is if a transaction Ti needs to access the entire database, and a locking protocol is used, then Ti must lock each item in the database.
Suppose another transaction just needs to access a few data items from a database, so locking the entire database seems to be unnecessary moreover it may cost us a loss of Concurrency, which was our primary goal in the first place. To bargain between Efficiency and Concurrency. Use Granularity.
Let's start by understanding what is meant by Granularity.
Granularity
It is the size of the data item allowed to lock. Now Multiple Granularity means hierarchically breaking up the database into blocks that can be locked and can be tracked what needs to lock and in what fashion. Such a hierarchy can be represented graphically as a tree.
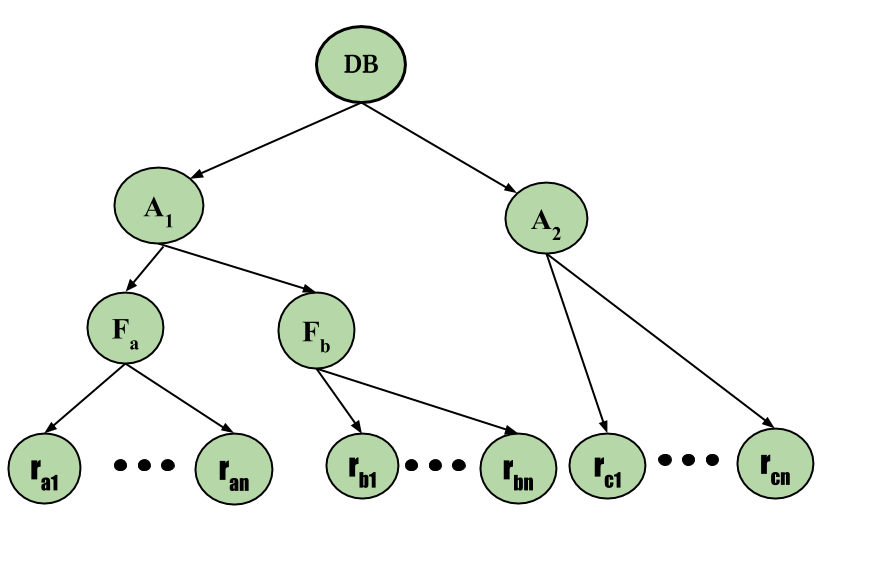
For example, consider the tree, which consists of four levels of nodes. The highest level represents the entire database. Below it is nodes of type area; the database consists of exactly these areas. The area has children nodes which are called files. Every area has those files that are its child nodes. No file can span more than one area.
Finally, each file has child nodes called records. As before, the file consists of exactly those records that are its child nodes, and no record can be present in more than one file. Hence, the levels starting from the top level are:
- Database
- Area
- File
- Record
 Multi Granularity tree Hiererchy
Multi Granularity tree Hiererchy
Consider the above diagram for the example given, each node in the tree can be locked individually. As in the 2-phase locking protocol, it shall use shared and exclusive lock modes. When a transaction locks a node, in either shared or exclusive mode, the transaction also implicitly locks all the descendants of that node in the same lock mode.
For example, if transaction Ti gets an explicit lock on file Fc in exclusive mode, then it has an implicit lock in exclusive mode on all the records belonging to that file. It does not need to lock the individual records of Fc explicitly. this is the main difference between Tree-Based Locking and Hierarchical locking for multiple granularities.
Now, with locks on files and records made simple, how does the system determine if the root node can be locked? One possibility is for it to search the entire tree but the solution nullifies the whole purpose of the multiple-granularity locking scheme. A more efficient way to gain this knowledge is to introduce a new lock mode, called Intention lock mode.
Intention Mode Lock
In addition to S and X lock modes, there are three additional lock modes with multiple granularities:
- Intention-Shared (IS): explicit locking at a lower level of the tree but only with shared locks.
- Intention-Exclusive (IX): explicit locking at a lower level with exclusive or shared locks.
- Shared & Intention-Exclusive (SIX): the subtree rooted by that node is locked explicitly in shared mode and explicit locking is being done at a lower level with exclusive mode locks.
The compatibility matrix for these lock modes are described below:
 Multi Granularity tree Hierarchy
Multi Granularity tree HierarchyThe multiple-granularity locking protocol uses the intention lock modes to ensure serializability. It requires that a transaction Ti that attempts to lock a node must follow these protocols:
- Transaction Ti must follow the lock-compatibility matrix.
- Transaction Ti must lock the root of the tree first, and it can lock it in any mode.
- Transaction Ti can lock a node in S or IS mode only if Ti currently has the parent of the node-locked in either IX or IS mode.
- Transaction Ti can lock a node in X, SIX, or IX mode only if Ti currently has the parent of the node-locked in either IX or SIX modes.
- Transaction Ti can lock a node only if Ti has not previously unlocked any node (i.e., Ti is two-phase).
- Transaction Ti can unlock a node only if Ti currently has none of the children of the node-locked.
Observe that the multiple-granularity protocol requires that locks be acquired in top-down (root-to-leaf) order, whereas locks must be released in bottom-up (leaf to-root) order.
As an illustration of the protocol, consider the tree given above and the transactions:
- Say transaction T1 reads record Ra2 in file Fa. Then, T1 needs to lock the database, area A1, and Fa in IS mode (and in that order), and finally to lock Ra2 in S mode.
- Say transaction T2 modifies record Ra9 in file Fa . Then, T2 needs to lock the database, area A1, and file Fa (and in that order) in IX mode, and at last to lock Ra9 in X mode.
- Say transaction T3 reads all the records in file Fa. Then, T3 needs to lock the database and area A1 (and in that order) in IS mode, and at last to lock Fa in S mode.
- Say transaction T4 reads the entire database. It can do so after locking the database in S mode.
Note: Transactions T1, T3 and T4 can access the database concurrently. Transaction T2 can execute concurrently with T1, but not with either T3 or T4.
This protocol enhances concurrency and reduces lock overhead. Deadlock is still possible in the multiple-granularity protocol, as it is in the two-phase locking protocol. These can be eliminated by using certain deadlock elimination techniques.
Similar Reads
Concurrency Control in DBMS In a database management system (DBMS), allowing transactions to run concurrently has significant advantages, such as better system resource utilization and higher throughput. However, it is crucial that these transactions do not conflict with each other. The ultimate goal is to ensure that the data
7 min read
Database Recovery Techniques in DBMS Database Systems like any other computer system, are subject to failures but the data stored in them must be available as and when required. When a database fails it must possess the facilities for fast recovery. It must also have atomicity i.e. either transactions are completed successfully and com
11 min read
ACID Properties in DBMS In the world of DBMS, transactions are fundamental operations that allow us to modify and retrieve data. However, to ensure the integrity of a database, it is important that these transactions are executed in a way that maintains consistency, correctness, and reliability. This is where the ACID prop
8 min read
Why recovery is needed in DBMS Basically, whenever a transaction is submitted to a DBMS for execution, the operating system is responsible for making sure or to be confirmed that all the operations which need to be performed in the transaction have been completed successfully and their effect is either recorded in the database or
6 min read
Types of Schedules in DBMS Schedule, as the name suggests, is a process of lining the transactions and executing them one by one. When there are multiple transactions that are running in a concurrent manner and the order of operation is needed to be set so that the operations do not overlap each other, Scheduling is brought i
7 min read
Conflict Serializability in DBMS A schedule is a sequence in which operations (read, write, commit, abort) from multiple transactions are executed in a database. Serial or one by one execution of schedules has less resource utilization and low throughput. To improve it, two or more transactions are run concurrently. Conflict Serial
5 min read
Precedence Graph for Testing Conflict Serializability in DBMS A Precedence Graph or Serialization Graph is used commonly to test the Conflict Serializability of a schedule. It is a directed Graph (V, E) consisting of a set of nodes V = {T1, T2, T3..........Tn} and a set of directed edges E = {e1, e2, e3..................em}. The graph contains one node for eac
6 min read
Recoverability in DBMS Recoverability is a critical feature of database systems. It ensures that after a failure, the database returns to a consistent state by permanently saving committed transactions and rolling back uncommitted ones. It relies on transaction logs to undo or redo changes as needed. This is crucial in mu
6 min read
Deadlock in DBMS In a Database Management System (DBMS), a deadlock occurs when two or more transactions are waiting indefinitely for one another to release resources (such as locks on tables, rows, or other database objects). This results in a situation where none of the transactions can proceed, effectively bringi
8 min read
Starvation in DBMS Starvation in DBMS is a problem that happens when some processes are unable to get the resources they need because other processes keep getting priority. This can happen in situations like locking or scheduling, where some processes keep getting the resources first, leaving others waiting indefinite
8 min read