Cycle Generative Adversarial Network (CycleGAN)
Last Updated : 30 May, 2025
Generative Adversarial Networks (GANs) use two neural networks i.e a generator that creates images and a discriminator that decides if those images look real or fake. Traditional GANs need paired data means each input image must have a matching output image. But finding such paired images is difficult which limits their practical use.
CycleGAN solves this problem by learning to change images from one style to another without needing matching pairs. It understands the features of the new style and transforms the original images accordingly. This makes it useful for tasks like changing seasons in photos, turning one animal into another or converting pictures into paintings. In this article we will see more about CycleGAN and its core concepts.
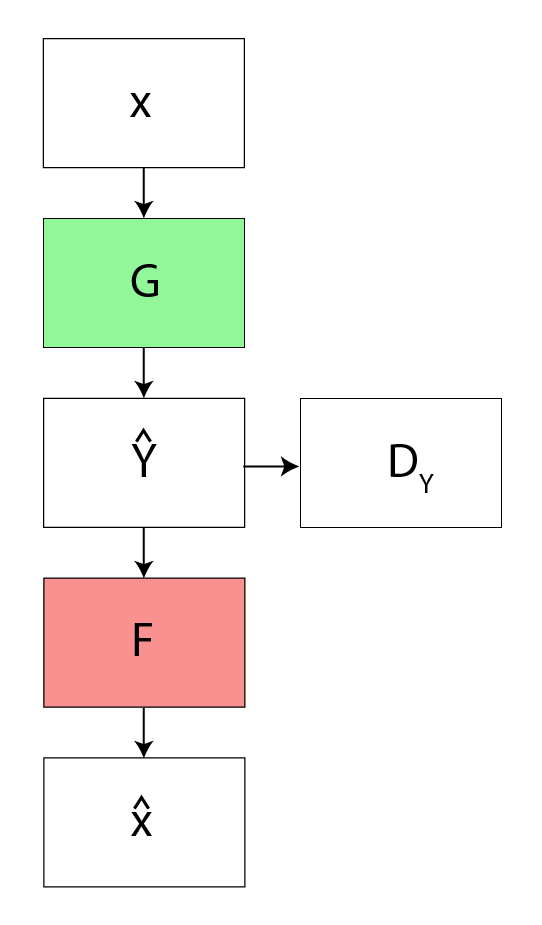
- The process starts with an input image(x) and Generator G translates it to the target domain like turning a photo into a painting. Then generator F takes this transformed image and maps it back to the original domain helps in reconstructing an image close to the input.
- The model measures the difference between the original and reconstructed images using a loss function like mean squared error. This cycle consistency loss helps the network to learn meaningful, reversible mappings between the two domains.

Architecture of CycleGAN
1. Generators: Create new images in the target style.
 CycleGAN has two generators G and F:
CycleGAN has two generators G and F:
- G transforms images from domain X like photos to domain Y like artwork.
- F transforms images from domain Y back to domain X.
The generator mapping functions are as follows:
\begin{array}{l} G : X \rightarrow Y \\ F : Y \rightarrow X \end{array}
where X is the input image distribution and Y is the desired output distribution such as Van Gogh styles.
2. Discriminators: Decide if images are real (from dataset) or fake (generated).
There are two discriminators Dₓ and Dᵧ.
- Dₓ distinguishes between real images from X and generated images from F(y).
- Dᵧ distinguishes between real images from Y and generated images from G(x).
To further regularize the mappings the CycleGAN uses two more loss function in addition to adversarial loss.
1. Forward Cycle Consistency Loss: Ensures that when we apply G and then F to an image we get back the original image
For example: .x --> G(x) -->F(G(x)) \approx x
2. Backward Cycle Consistency Loss: Ensures that when we apply F and then G to an image we get back the original image.
For example: x \xrightarrow{G} G(x) \xrightarrow{F} F(G(x)) \approx x


Generator Architecture
Each CycleGAN generator has three main sections:
- Encoder: The input image is passed through three convolution layers which extract features and compress the image while increasing the number of channels. For example a 256×256×3 image is reduced to 64×64×256 after this step.
- Transformer: The encoded image is processed through 6 or 9 residual blocks depending on the input size which helps retain important image details.
- Decoder: The transformed image is up-sampled using two deconvolution layers and restoring it to its original size.
Generator Structure:
c7s1-64 → d128 → d256 → R256 (×6 or 9) → u128 → u64 → c7s1-3
- c7s1-k: 7×7 convolution layer with k filters.
- dk: 3×3 convolution with stride 2 (down-sampling).
- Rk: Residual block with two 3×3 convolutions.
- uk: Fractional-stride deconvolution (up-sampling).

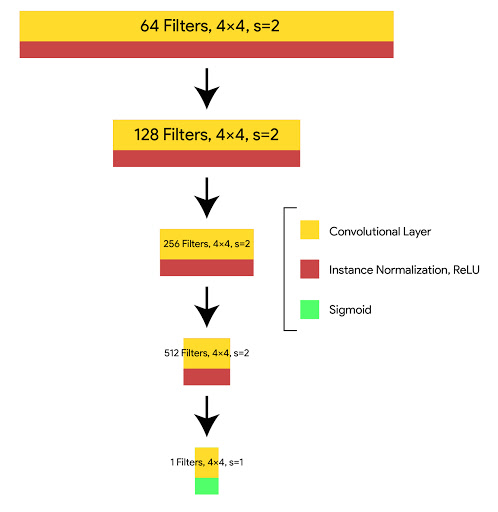
Discriminator Architecture (PatchGAN)
In CycleGAN the discriminator uses a PatchGAN instead of a regular GAN discriminator.
- A regular GAN discriminator looks at the entire image (e.g 256×256 pixels) and outputs a single score that says whether the whole image is real or fake.
- PatchGAN breaks the image into smaller patches (e.g 70×70 patches). It outputs a grid (like 70×70 values) where each value judges if the corresponding patch is real or fake.
This lets PatchGAN focus on local details such as textures and small patterns rather than the whole image at once it helps in improving the quality of generated images.
Discriminator Structure:
C64 → C128 → C256 → C512 → Final Convolution
- Ck: 4×4 convolution with k filters, InstanceNorm and LeakyReLU except the first layer.
- The final layer produces a 1×1 output and marking real vs. fake patches.
Cost Function in CycleGAN
CycleGAN uses a cost function or loss function to help the training process. The cost function is made up of several parts:
- Adversarial Loss: We apply adversarial loss to both our mappings of generators and discriminators. This adversary loss is written as :
Loss_{advers}\left ( G, D_y, X, Y \right ) =\frac{1}{m}\sum \left ( 1 - D_y\left ( G\left ( x \right ) \right ) \right )^{2}
Loss_{advers}\left ( F, D_x, Y, X \right ) =\frac{1}{m}\sum \left ( 1 - D_x\left ( F\left ( y \right ) \right ) \right )^{2}
- Cycle Consistency Loss: Given a random set of images adversarial network can map the set of input image to random permutation of images in the output domain which may induce the output distribution similar to target distribution. Thus adversarial mapping cannot guarantee the input xi to yi . For this to happen we proposed that process should be cycle-consistent. This loss function used in Cycle GAN to measure the error rate of inverse mapping G(x) -> F(G(x)). The behavior induced by this loss function cause closely matching the real input (x) and F(G(x))
Loss_{cyc}\left ( G, F, X, Y \right ) =\frac{1}{m}\left [ \left ( F\left ( G\left ( x_i \right ) \right )-x_i \right ) +\left ( G\left ( F\left ( y_i \right ) \right )-y_i \right ) \right ]
The Cost function we used is the sum of adversarial loss and cyclic consistent loss:
L\left ( G, F, D_x, D_y \right ) = L_{advers}\left (G, D_y, X, Y \right ) + L_{advers}\left (F, D_x, Y, X \right ) + \lambda L_{cycl}\left ( G, F, X, Y \right )
and our aim is :
arg \underset{G, F}{min}\underset{D_x, D_y}{max}L\left ( G, F, D_x, D_y \right )
Applications of CycleGAN in Image Translation
1. Collection Style Transfer: CycleGAN can learn to mimic the style of entire collections of artworks like Van Gogh, Monet or Cezanne rather than just transferring the style of a single image. Therefore it can generate different styles such as : Van Gogh, Cezanne, Monet and Ukiyo-e. This capability makes CycleGAN particularly useful for generating diverse artwork.
 Style Transfer Results
Style Transfer Results Comparison of different Style Transfer Results
Comparison of different Style Transfer Results2. Object Transformation: CycleGAN can transform objects between different classes, such as turning zebras into horses, apples into oranges or vice versa. This is especially useful for creative industries and content generation.

3. Seasonal Transfer: CycleGAN can be used for seasonal image transformation, such as converting winter photos to summer scenes and vice versa. For instance, it was trained on photos of Yosemite in both winter and summer to enable this transformation.

4. Photo Generation from Paintings: CycleGAN can transform a painting into a photo and vice versa. This is useful for artistic applications where you want to blend the look of photos with artistic styles. This loss can be defined as :
L_{identity}\left ( G, F \right ) =\mathbb{E}_{y~p\left ( y \right )}\left [ \left \| G(y)-y \right \|_1 \right ] + \mathbb{E}_{x~p\left ( x \right )}\left [ \left \| F(x)-x \right \|_1 \right ]

5. Photo Enhancement: CycleGAN can enhance photos taken with smartphone cameras which typically have a deeper depth of field to look like those taken with DSLR cameras which have a shallower depth of field. This application is valuable for image quality improvement.

- AMT Perceptual Studies: It involve real people reviewing generated images to see if they look real. This is like a voting system where participants on Amazon Mechanical Turk compare AI-created images with actual ones.
- FCN Scores: It help to measure accuracy especially in datasets like Cityscapes. These scores check how well the AI understands objects in images by evaluating pixel accuracy and IoU (Intersection over Union) which measures how well the shapes of objects match real.
Drawbacks and Limitations
- CycleGAN is great at modifying textures like turning a horse’s coat into zebra stripes but cannot significantly change object shapes or structures.
- The model is trained to change colors and patterns rather than reshaping objects and make structural modifications difficult.
- Sometimes it give the unpredictable results like the generated images may look unnatural or contain distortions.
Similar Reads
Deep Learning Tutorial Deep Learning tutorial covers the basics and more advanced topics, making it perfect for beginners and those with experience. Whether you're just starting or looking to expand your knowledge, this guide makes it easy to learn about the different technologies of Deep Learning.Deep Learning is a branc
5 min read
Introduction to Deep Learning
Basic Neural Network
Activation Functions
Artificial Neural Network
Classification
Regression
Hyperparameter tuning
Introduction to Convolution Neural Network
Introduction to Convolution Neural NetworkConvolutional Neural Network (CNN) is an advanced version of artificial neural networks (ANNs), primarily designed to extract features from grid-like matrix datasets. This is particularly useful for visual datasets such as images or videos, where data patterns play a crucial role. CNNs are widely us
8 min read
Digital Image Processing BasicsDigital Image Processing means processing digital image by means of a digital computer. We can also say that it is a use of computer algorithms, in order to get enhanced image either to extract some useful information. Digital image processing is the use of algorithms and mathematical models to proc
7 min read
Difference between Image Processing and Computer VisionImage processing and Computer Vision both are very exciting field of Computer Science. Computer Vision: In Computer Vision, computers or machines are made to gain high-level understanding from the input digital images or videos with the purpose of automating tasks that the human visual system can do
2 min read
CNN | Introduction to Pooling LayerPooling layer is used in CNNs to reduce the spatial dimensions (width and height) of the input feature maps while retaining the most important information. It involves sliding a two-dimensional filter over each channel of a feature map and summarizing the features within the region covered by the fi
5 min read
CIFAR-10 Image Classification in TensorFlowPrerequisites:Image ClassificationConvolution Neural Networks including basic pooling, convolution layers with normalization in neural networks, and dropout.Data Augmentation.Neural Networks.Numpy arrays.In this article, we are going to discuss how to classify images using TensorFlow. Image Classifi
8 min read
Implementation of a CNN based Image Classifier using PyTorchIntroduction: Introduced in the 1980s by Yann LeCun, Convolution Neural Networks(also called CNNs or ConvNets) have come a long way. From being employed for simple digit classification tasks, CNN-based architectures are being used very profoundly over much Deep Learning and Computer Vision-related t
9 min read
Convolutional Neural Network (CNN) ArchitecturesConvolutional Neural Network(CNN) is a neural network architecture in Deep Learning, used to recognize the pattern from structured arrays. However, over many years, CNN architectures have evolved. Many variants of the fundamental CNN Architecture This been developed, leading to amazing advances in t
11 min read
Object Detection vs Object Recognition vs Image SegmentationObject Recognition: Object recognition is the technique of identifying the object present in images and videos. It is one of the most important applications of machine learning and deep learning. The goal of this field is to teach machines to understand (recognize) the content of an image just like
5 min read
YOLO v2 - Object DetectionIn terms of speed, YOLO is one of the best models in object recognition, able to recognize objects and process frames at the rate up to 150 FPS for small networks. However, In terms of accuracy mAP, YOLO was not the state of the art model but has fairly good Mean average Precision (mAP) of 63% when
7 min read
Recurrent Neural Network
Natural Language Processing (NLP) TutorialNatural Language Processing (NLP) is a branch of Artificial Intelligence (AI) that helps machines to understand and process human languages either in text or audio form. It is used across a variety of applications from speech recognition to language translation and text summarization.Natural Languag
5 min read
NLTK - NLPNatural Language Toolkit (NLTK) is one of the largest Python libraries for performing various Natural Language Processing tasks. From rudimentary tasks such as text pre-processing to tasks like vectorized representation of text - NLTK's API has covered everything. In this article, we will accustom o
5 min read
Word Embeddings in NLPWord Embeddings are numeric representations of words in a lower-dimensional space, that capture semantic and syntactic information. They play a important role in Natural Language Processing (NLP) tasks. Here, we'll discuss some traditional and neural approaches used to implement Word Embeddings, suc
14 min read
Introduction to Recurrent Neural NetworksRecurrent Neural Networks (RNNs) differ from regular neural networks in how they process information. While standard neural networks pass information in one direction i.e from input to output, RNNs feed information back into the network at each step.Imagine reading a sentence and you try to predict
10 min read
Recurrent Neural Networks ExplanationToday, different Machine Learning techniques are used to handle different types of data. One of the most difficult types of data to handle and the forecast is sequential data. Sequential data is different from other types of data in the sense that while all the features of a typical dataset can be a
8 min read
Sentiment Analysis with an Recurrent Neural Networks (RNN)Recurrent Neural Networks (RNNs) are used in sequence tasks such as sentiment analysis due to their ability to capture context from sequential data. In this article we will be apply RNNs to analyze the sentiment of customer reviews from Swiggy food delivery platform. The goal is to classify reviews
5 min read
Short term MemoryIn the wider community of neurologists and those who are researching the brain, It is agreed that two temporarily distinct processes contribute to the acquisition and expression of brain functions. These variations can result in long-lasting alterations in neuron operations, for instance through act
5 min read
What is LSTM - Long Short Term Memory?Long Short-Term Memory (LSTM) is an enhanced version of the Recurrent Neural Network (RNN) designed by Hochreiter and Schmidhuber. LSTMs can capture long-term dependencies in sequential data making them ideal for tasks like language translation, speech recognition and time series forecasting. Unlike
5 min read
Long Short Term Memory Networks ExplanationPrerequisites: Recurrent Neural Networks To solve the problem of Vanishing and Exploding Gradients in a Deep Recurrent Neural Network, many variations were developed. One of the most famous of them is the Long Short Term Memory Network(LSTM). In concept, an LSTM recurrent unit tries to "remember" al
7 min read
LSTM - Derivation of Back propagation through timeLong Short-Term Memory (LSTM) are a type of neural network designed to handle long-term dependencies by handling the vanishing gradient problem. One of the fundamental techniques used to train LSTMs is Backpropagation Through Time (BPTT) where we have sequential data. In this article we see how BPTT
4 min read
Text Generation using Recurrent Long Short Term Memory NetworkLSTMs are a type of neural network that are well-suited for tasks involving sequential data such as text generation. They are particularly useful because they can remember long-term dependencies in the data which is crucial when dealing with text that often has context that spans over multiple words
4 min read