Context-Free Grammars (CFGs) is a way to describe the structure of a language, such as the rules for building sentences in a language or programming code. These rules help define how different symbols can be combined to create valid strings (sequences of symbols).
CFGs can be divided into two types based on how they create derivation trees :
- Ambiguous grammars: These grammars can create more than one derivation tree for the same string. This means that a string can have different meanings or interpretations depending on how it's parsed.
- Unambiguous grammars: These grammars only allow one derivation tree for each string, so there's no confusion about how the string should be interpreted.
This classification helps us to understand how CFGs are used in language and computer systems to process information.
Ambiguous grammar
A Context-Free Grammar (CFG) is called ambiguous if there is a string that can have more than one valid derivation tree. This means the string can be generated in different ways, either through different LeftMost Derivations (LMDT) or RightMost Derivations (RMDT).
In simple terms, a CFG G = (V, T, P, S) is ambiguous if there is a string in the terminal set T that can be produced in more than one way, creating multiple parse trees. Here:
- V is the set of variables (non-terminal symbols),
- T is the set of terminal symbols,
- P is the set of production rules,
- S is the start symbol, which is a special variable from where the derivation begins.
This happens when a string has multiple possible ways to be derived using the grammar rules, leading to more than one valid tree structure.
Example 1. Let us consider this grammar: E-> E +E | E*E| id, We can create 2 parse tree from this grammar to obtain a string id + id * id.

Both the above parse trees are derived from the same grammar rules but both parse trees are different. Hence the grammar is ambiguous.
Example 2. Let us now consider the following grammar:
Set of alphabets ? = {0,…,9, +, *, (, )}
E -> I
E -> E + E
E -> E * E
E -> (E)
I -> ? | 0 | 1 | … | 9
From the above grammar String 3*2+5 can be derived in 2 ways:
I) First leftmost derivation II) Second leftmost derivation
E=>E*E E=>E+E
=>I*E =>E*E+E
=>3*E+E =>I*E+E
=>3*I+E =>3*E+E
=>3*2+E =>3*I+E
=>3*2+I =>3*2+I
=>3*2+5 =>3*2+5
Following are some examples of ambiguous grammar:
- S-> aS |Sa| ?
- E-> E +E | E*E| id
- A -> AA | (A) | a
- S -> SS|AB , A -> Aa|a , B -> Bb|b
Whereas following grammars are unambiguous:
- S -> (L) | a, L -> LS | S
- S -> AA , A -> aA , A -> b
Removal of Ambiguity in Grammar
To remove ambiguity from a grammar, follow these simple steps:
- Simplify production rules: Break down complex rules into smaller and simpler ones. This way, the grammar won't allow multiple interpretations for the same string.
- Set precedence and associativity: For things like math operations, make sure the order in which they are applied is clear. For example, define that multiplication happens before addition, or how to group operations (left-to-right or right-to-left).
- Fix left recursion: Left recursion occurs when a rule refers to itself in a way that causes infinite loops. To fix it, change the rules so that recursion happens at the end, not at the start.
- Factor out common parts: If two rules start the same way, combine the common part. For example, instead of having rules like A → αβ and A → αγ, make it A → αA' and A' → β | γ.
Read more about Removal of Ambiguity in Grammar.
Inherent Ambiguity
A Context-Free Language (CFL) is said to be inherently ambiguous if every possible grammar for the language is ambiguous. This means no matter how you write the grammar for the language, there will always be strings in that language that can be parsed in more than one way.
Example:
Consider the language L defined as:
L = { aⁿbⁿcᵐdᵐ : n ≥ 1, m ≥ 1 } ∪ { aⁿbᵐcᵐdⁿ : n ≥ 1, m ≥ 1 }
A grammar for this language could be:
- S → AB | C
- A → aAb | ab
- B → cBd | cd
- C → aCd | aDd
- D → bDc | bc
Let’s see how the string aabbccdd can be parsed. This string has two possible leftmost derivations:
Using S → AB:
- S ⇒ AB
- A → aAb ⇒ aAbB
- A → ab ⇒ aabbB
- B → cBd ⇒ aabbcBd
- B → cd ⇒ aabbccdd
Using S → C:
- S ⇒ C
- C → aCd ⇒ aCd
- C → aDd ⇒ aaDdd
- D → bDc ⇒ aabDcdd
- D → bc ⇒ aabbccdd
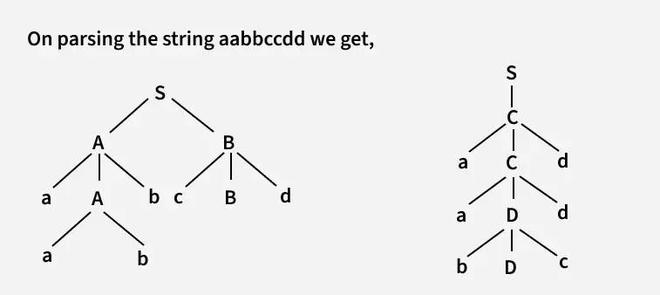
Both derivations result in the same string aabbccdd, but they come from different rules and paths, showing that there is more than one way to parse the string.
Since there are multiple ways to parse the string aabbccdd and this pattern holds for all grammars of L, we can conclude that L is inherently ambiguous. This means no grammar for L can avoid ambiguity for all strings in the language.
Important Points on Ambiguous Grammar
1) A grammar is ambiguous if it contains both left recursion and right recursion. This combination can lead to multiple ways of deriving the same string, creating more than one parse tree.
Example: S → SaS | ε
Here, the grammar has both left recursion (S → SaS) and right recursion (S → ε), making it ambiguous. This allows multiple derivations for the same string, such as {aa}, leading to more than one parse tree.

2) Even if a grammar does not have both left and right recursion, it can still be ambiguous. The absence of recursion does not guarantee that the grammar is unambiguous.
Example: S → aB | ab , A → AB | a , B → Abb | b
In this example, there is no left or right recursion, but the grammar is still ambiguous. For the string {ab}, we can derive it in multiple ways, resulting in more than one parse tree. This shows that even without recursion, a grammar can still be ambiguous.

From the above example, we can see that even if both left and right recursion are not present in grammar, the grammar can be ambiguous.
Similar Reads
Introduction of Compiler Design A compiler is software that translates or converts a program written in a high-level language (Source Language) into a low-level language (Machine Language or Assembly Language). Compiler design is the process of developing a compiler.The development of compilers is closely tied to the evolution of
9 min read
Compiler Design Basics
Introduction of Compiler DesignA compiler is software that translates or converts a program written in a high-level language (Source Language) into a low-level language (Machine Language or Assembly Language). Compiler design is the process of developing a compiler.The development of compilers is closely tied to the evolution of
9 min read
Compiler construction toolsThe compiler writer can use some specialized tools that help in implementing various phases of a compiler. These tools assist in the creation of an entire compiler or its parts. Some commonly used compiler construction tools include: Parser Generator - It produces syntax analyzers (parsers) from the
4 min read
Phases of a CompilerA compiler is a software tool that converts high-level programming code into machine code that a computer can understand and execute. It acts as a bridge between human-readable code and machine-level instructions, enabling efficient program execution. The process of compilation is divided into six p
10 min read
Symbol Table in CompilerEvery compiler uses a symbol table to track all variables, functions, and identifiers in a program. It stores information such as the name, type, scope, and memory location of each identifier. Built during the early stages of compilation, the symbol table supports error checking, scope management, a
8 min read
Error Handling in Compiler DesignDuring the process of language translation, the compiler can encounter errors. While the compiler might not always know the exact cause of the error, it can detect and analyze the visible problems. The main purpose of error handling is to assist the programmer by pointing out issues in their code. E
5 min read
Language Processors: Assembler, Compiler and InterpreterComputer programs are generally written in high-level languages (like C++, Python, and Java). A language processor, or language translator, is a computer program that convert source code from one programming language to another language or to machine code (also known as object code). They also find
5 min read
Generation of Programming LanguagesProgramming languages have evolved significantly over time, moving from fundamental machine-specific code to complex languages that are simpler to write and understand. Each new generation of programming languages has improved, allowing developers to create more efficient, human-readable, and adapta
6 min read
Lexical Analysis
Introduction of Lexical AnalysisLexical analysis, also known as scanning is the first phase of a compiler which involves reading the source program character by character from left to right and organizing them into tokens. Tokens are meaningful sequences of characters. There are usually only a small number of tokens for a programm
6 min read
Flex (Fast Lexical Analyzer Generator)Flex (Fast Lexical Analyzer Generator), or simply Flex, is a tool for generating lexical analyzers scanners or lexers. Written by Vern Paxson in C, circa 1987, Flex is designed to produce lexical analyzers that is faster than the original Lex program. Today it is often used along with Berkeley Yacc
7 min read
Introduction of Finite AutomataFinite automata are abstract machines used to recognize patterns in input sequences, forming the basis for understanding regular languages in computer science. They consist of states, transitions, and input symbols, processing each symbol step-by-step. If the machine ends in an accepting state after
4 min read
Classification of Context Free GrammarsA Context-Free Grammar (CFG) is a formal rule system used to describe the syntax of programming languages in compiler design. It provides a set of production rules that specify how symbols (terminals and non-terminals) can be combined to form valid sentences in the language. CFGs are important in th
4 min read
Ambiguous GrammarContext-Free Grammars (CFGs) is a way to describe the structure of a language, such as the rules for building sentences in a language or programming code. These rules help define how different symbols can be combined to create valid strings (sequences of symbols).CFGs can be divided into two types b
7 min read
Syntax Analysis & Parsers
Syntax Directed Translation & Intermediate Code Generation
Syntax Directed Translation in Compiler DesignSyntax-Directed Translation (SDT) is a method used in compiler design to convert source code into another form while analyzing its structure. It integrates syntax analysis (parsing) with semantic rules to produce intermediate code, machine code, or optimized instructions.In SDT, each grammar rule is
8 min read
S - Attributed and L - Attributed SDTs in Syntax Directed TranslationIn Syntax-Directed Translation (SDT), the rules are those that are used to describe how the semantic information flows from one node to the other during the parsing phase. SDTs are derived from context-free grammars where referring semantic actions are connected to grammar productions. Such action c
4 min read
Parse Tree and Syntax TreeParse Tree and Syntax tree are tree structures that represent the structure of a given input according to a formal grammar. They play an important role in understanding and verifying whether an input string aligns with the language defined by a grammar. These terms are often used interchangeably but
4 min read
Intermediate Code Generation in Compiler DesignIn the analysis-synthesis model of a compiler, the front end of a compiler translates a source program into an independent intermediate code, then the back end of the compiler uses this intermediate code to generate the target code (which can be understood by the machine). The benefits of using mach
6 min read
Issues in the design of a code generatorA code generator is a crucial part of a compiler that converts the intermediate representation of source code into machine-readable instructions. Its main task is to produce the correct and efficient code that can be executed by a computer. The design of the code generator should ensure that it is e
7 min read
Three address code in CompilerTAC is an intermediate representation of three-address code utilized by compilers to ease the process of code generation. Complex expressions are, therefore, decomposed into simple steps comprising, at most, three addresses: two operands and one result using this code. The results from TAC are alway
6 min read
Data flow analysis in CompilerData flow is analysis that determines the information regarding the definition and use of data in program. With the help of this analysis, optimization can be done. In general, its process in which values are computed using data flow analysis. The data flow property represents information that can b
6 min read
Code Optimization & Runtime Environments
Practice Questions