Statistical machine translation (SMT) is a type of machine translation (MT) that uses statistical models to translate text from one language to another. Unlike traditional rule-based systems, SMT relies on large bilingual text corpora to build probabilistic models that determine the likelihood of a sentence in the target language given a sentence in the source language. This approach marked a significant shift in natural language processing (NLP) and opened the door for more advanced machine translation technologies.
In this article, we'll explore the concept of Statistical Machine Translation, how it works, its components, and its impact on the field of AI and NLP.
Overview on Statistical Machine Translation in Artificial Intelligence
Statistical Machine Translation (SMT) works by analyzing large bilingual corpora, such as parallel texts or sentence-aligned translation pairs, to identify patterns and relationships between words and phrases in different languages. These patterns are then used to build probabilistic models that can generate translations for new sentences or documents.
Given the complexity of translation, it is not surprising that the most effective machine translation systems are developed by training a probabilistic model on statistics derived from a vast corpus of text. This method does not require a complicated ontology of interlingua concepts, handcrafted source and target language grammars, or a manually labeled treebank. Instead, it simply requires data in the form of example translations from which a translation model can be learned.
To formalize this, SMT determines the translation f^* that maximizes the conditional probability P(f \mid e), where:
- f is the translation (in the target language),
- e is the original sentence (in the source language),
- P(f \mid e) is the probability of the translation f given the sentence e.
The goal is to find the string of words f^* that maximizes this probability:
f^* = \underset{f}{\operatorname{argmax}} \ P(f \mid e)
Using Bayes' theorem, this can be rewritten as:
f^* = \underset{f}{\operatorname{argmax}} \ P(e \mid f) \cdot P(f)
Here:
- P(e \mid f) represents the translation model, which gives the probability of the source sentence given the target translation.
- P(f) is the language model, which estimates the probability of the target sentence being grammatically correct and fluent.
In summary, SMT involves finding the translation f^* that maximizes the product of the language model and the translation model, leveraging a large amount of bilingual data to automatically learn the translation process.
Why Statistical Machine Translation is Needed in AI?
SMT serves as a crucial tool in artificial intelligence for several reasons:
- Efficiency: SMT is much faster than traditional human translation, offering a cost-effective solution for businesses with extensive translation needs.
- Scalability: It can handle high-volume translation tasks, enabling global communication for businesses and organizations across different languages.
- Quality: With improvements in machine learning and deep learning, SMT models have become more reliable, producing translations that are approaching the quality of human translators.
- Accessibility: SMT plays a critical role in making digital content accessible to users who speak different languages, thereby expanding the global reach of products and services.
- Language Learning: For language learners, SMT provides valuable insights into unfamiliar words and phrases, helping them improve their understanding and language skills.
How SMT Works: Translating from English to French
To explain SMT in action, consider the task of translating a sentence from English (e) to French (f). The translation model, represented as P(f|e), helps determine the probability of a French sentence given its English counterpart. SMT often employs Bayes' rule to utilize the reverse model P(e|f)P(f), which helps break down complex sentences into manageable components, eventually translating them into coherent phrases in the target language.
The language model P(f) helps define how likely a given sentence is in French, while the translation model P(e|f) defines how likely an English sentence is to translate into a French sentence. This bilingual corpus-based approach allows SMT to handle vast linguistic structures and provide accurate translations.

The language model, P(f), might address any level(s) on the right-hand side of the figure above, but the simplest and most frequent technique, as we've seen before, is to develop an n-gram model from a French corpus. This just catches a partial, local sense of French phrases, but it's typically enough for a rudimentary translation.
Parallel Texts and Training the Translation Model
Statistical Machine Translation (SMT) relies on a collection of parallel texts (bilingual corpora), where each pair contains aligned sentences, such as English/French pairs. If we had access to an endlessly large corpus, translation would simply involve looking up the sentence: every English sentence would already have a corresponding French translation. However, in real-world applications, resources are limited, and most sentences encountered during translation are new. Fortunately, many of these sentences are composed of terms or phrases seen before, even if they are as short as one word.
For instance, phrases like "in this exercise we shall," "size of the state space," "as a function of," and "notes at the conclusion of the chapter" are common.
Given the sentence: "In this exercise, we will compute the size of the state space as a function of the number of actions,"
SMT can break it down into phrases, identify corresponding English and French equivalents from the corpus, and then reorder them in a way that makes sense in French.
Three-Step Process for Translating English to French
Given an English sentence e, the translation into French f involves three steps:
- Phrase Segmentation: Divide the English sentence into segments e_1, e_2, \ldots, e_n.
- Phrase Matching: For each English segment e_i, select a corresponding French phrase f_i. The likelihood that f_i is the translation of e_i is represented as: P(f_i \mid e_i)
- Phrase Reordering: After selecting the French phrases f_1, f_2, \ldots, f_n, reorder them into a coherent French sentence. This step involves choosing a distortion d_i for each French phrase fif_ifi, which indicates how far the phrase has moved relative to the previous phrase f_{i-1}: d_i = \operatorname{START}(f_i) - \operatorname{END}(f_{i-1}) - 1 . Here, \operatorname{START}(f_i) is the position of the first word in f_i in the French sentence, and is \operatorname{END}(f_{i-1})the position of the last word in f_{i-1}.
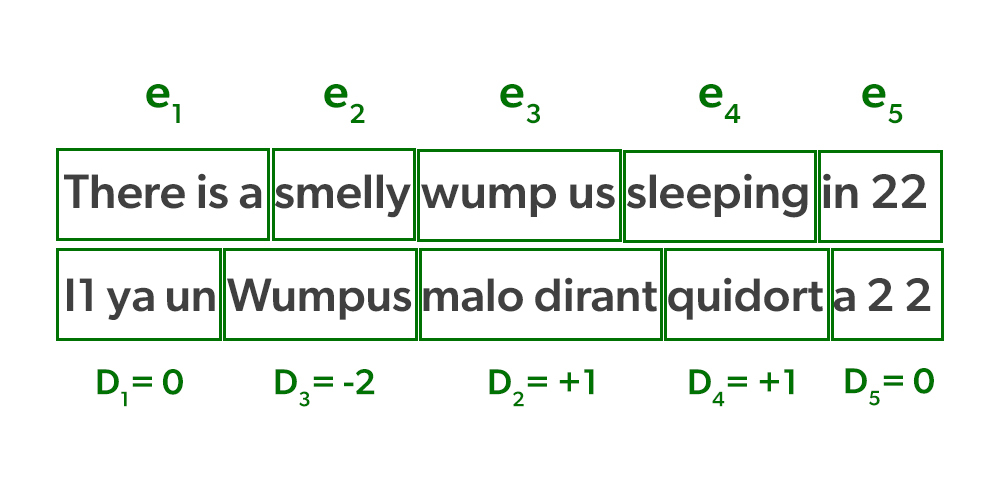
Example: Reordering with Distortion
Consider the sentence: "There is a stinky wumpus sleeping in 2 2."
- The sentence is divided into five phrases: e_1, e_2, e_3, e_4, e_5.
- Each English phrase is translated into a French phrase: f_1, f_2, f_3, f_4, f_5.
- The French phrases are reordered as f_1, f_3, f_4, f_2, f_5.
This reordering is determined by the distortion d_i, which shows how much each phrase has shifted. For example:
- f_5 comes immediately after f_4, so d_5 = 0.
- f_2 has shifted one position to the right of f_1, so d_2 = 1.
Defining Distortion Probability
Now that the distortion d_i has been defined, we can specify the probability distribution for distortion P(d_i). Since each phrase f_i can move by up to n positions (both left and right), the probability distribution \mathbf{P}(d_i) contains 2n + 1 elements—far fewer than the number of permutations n!.
This simplified distortion model does not consider grammatical rules like adjective-noun placement in French, which is handled by the French language model P(f). The distortion probability focuses solely on the integer value d_i and summarizes the likelihood of phrase shifts during translation.
For instance, it compares how often a shift of P(d = 2) occurs relative to P(d=0).
Combining the Translation and Distortion Models
The probability that a series of French words f, with distortions d, is a translation of an English sentence e, can be written as:
P(f, d \mid e) = \prod P(f_i \mid e_i) P(d_i)
Here, we assume that each phrase translation and distortion is independent of the others. This formula allows us to calculate the probability P(f, d \mid e) for a given translation f and distortion d. However, with around 100 French phrases corresponding to each English phrase in the corpus, and 5! reorderings for each sentence, there are thousands of potential translations and permutations. Therefore, finding the optimal translation requires a local beam search and a heuristic that evaluates the likelihood of different translation candidates.
Phrasal and Distortion Probability Estimation
The final step is estimating the probabilities of phrase translation and distortion. Here's an overview of the process:
- Find Similar Texts: Start by gathering a bilingual corpus. For example, bilingual Hansards (parliamentary records) are available in countries like Canada and Hong Kong. Other sources include the European Union’s official documents (in 11 languages), United Nations multilingual publications, and online sites with parallel URLs (e.g.,
/en/ for English and /fr/ for French). These corpora, combined with large monolingual texts, provide the training data for SMT models. - Sentence Segmentation: Since translation works at the sentence level, the corpus must be divided into sentences. Periods are typically reliable markers, but not always. For example, in the sentence:
"Dr. J. R. Smith of Rodeo Dr. paid $29.99 on September 9, 2009."
only the final period ends the sentence. A model trained on the surrounding words and their parts of speech can achieve 98% accuracy in sentence segmentation. - Sentence Alignment: Match each sentence in the English text with its corresponding French sentence. In most cases, this is a simple 1:1 alignment, but some cases may require a 2:1 or even 2:2 alignment. Sentence lengths can be used for initial alignment, with accuracy between 90-99%. Using landmarks like dates, proper nouns, or numbers improves alignment accuracy.
- Phrase Alignment: After sentence alignment, phrase alignment within each sentence is performed. This iterative process accumulates evidence from the corpus. For instance, if "qui dort" frequently co-occurs with "sleeping" in the training data, they are likely aligned. After smoothing, the phrasal probabilities are computed.
- Defining Distortion Probabilities: Once the phrase alignment is established, distortion probabilities are calculated. The distortion d = 0, \pm 1, \pm 2, \ldots is counted and then smoothed to obtain a more generalizable probability distribution.
- Expectation-Maximization (EM) Algorithm: The EM algorithm is used to improve the estimates of P(f \mid e) and P(d). In the E-step, the best alignments are computed using the current parameter estimates. In the M-step, these estimates are updated, and the process is repeated until convergence is achieved.
Advantages of Statistical Machine Translation
- Data-Driven: SMT is highly data-driven and doesn’t rely on hand-crafted linguistic rules, making it adaptable to different language pairs and domains.
- Scalability: Given sufficient parallel corpora, SMT can scale across many languages, allowing for the creation of translation systems for lesser-known languages.
- Flexibility: SMT models can handle idiomatic expressions and language-specific nuances better than rule-based systems by using statistical patterns found in real-world data.
Challenges of Statistical Machine Translation in AI
Despite its advantages, SMT faces several challenges:
- Data Quality and Availability: SMT models rely heavily on large bilingual corpora. For lesser-known languages, obtaining high-quality data can be a significant challenge, impacting the accuracy of translations.
- Domain-Specific Knowledge: SMT struggles with specialized areas like legal or medical translations, where specific terminology and context are crucial.
- Linguistic Complexity: SMT often struggles with idiomatic expressions, ambiguous syntax, and cultural nuances, leading to incorrect translations.
- Accuracy vs. Fluency: SMT models may produce accurate translations that lack natural fluency, making the text sound awkward.
- Bias and Cultural Sensitivity: Like all AI models, SMT can reflect biases in training data, sometimes resulting in inappropriate translations.
- Lack of Context: Without proper context, SMT may generate translations that are contextually incorrect or irrelevant.
- Post-Editing Needs: Even with the best models, human translators are often required for post-editing to ensure the final translation's accuracy and quality.
Conclusion
SMT continues to evolve, especially with advances in neural network models. Despite the challenges, its ability to efficiently process large-scale translations with reasonable accuracy makes it a critical tool in AI and NLP. By continuously improving data quality, adapting domain-specific knowledge, and addressing linguistic complexities, SMT holds significant potential to transform how we communicate across languages.
Similar Reads
Artificial Intelligence | Natural Language Generation Artificial Intelligence, defined as intelligence exhibited by machines, has many applications in today's society. One of its applications, most widely used is natural language generation. What is Natural Language Generation (NLG)?Natural Language Generation (NLG) simply means producing text from com
10 min read
Top 5 Programming Languages For Artificial Intelligence In recent years, Artificial Intelligence has seen exponential growth and innovation in the field of technology. As the demand for Artificial intelligence among companies and developers is continuously increasing and several programming languages have emerged as popular choices for the Artificial Int
5 min read
Syntactically analysis in Artificial Intelligence In this article, we are going to see about syntactically analysing in Artificial Intelligence. Parsing is the process of studying a string of words in order to determine its phrase structure using grammatical rules. We can start with the S sign and search top-down for a tree with the words as its le
5 min read
Linguistic intelligence in AI The reason why linguistic intelligence is significant in artificial intelligence is due to its function of allowing machines recognize and generate human dialect. The article considers how linguistic intelligence contributes to AI, its basic principles, applications and prospects. Table of Content W
6 min read
How Python is Shaping the Future of Artificial Intelligence Python has established itself as the go-to programming language for Artificial Intelligence (AI) and machine learning. Its simplicity, flexibility, and vast library ecosystem make it indispensable for both beginners and experienced AI practitioners. In recent years, the use of Python in AI has soare
5 min read